本篇介紹如何在 Ubuntu Linux 中安裝與設定 Prometheus 與 Grafana,用來監控伺服器狀態、發送告警 Email 簡訊。
在管理者用來監控系統狀態的伺服器上,安裝 prometheus 套件:
# 安裝 prometheus 套件
sudo apt install prometheus
Prometheus 伺服器本身的設定檔位於 /etc/default/prometheus,在這個設定檔中可以調整 Prometheus 伺服器傾聽的網路介面與連接埠、資料保存時間、記錄檔層級等系統面的設定,也就是啟動 Prometheus 伺服器時傳遞給 Prometheus 伺服器的指令參數。以下是一個簡單的設定範例:
# 指定 Prometheus 伺服器傾聽 0.0.0.0:9090,資料保存時間為 15 天 ARGS="--web.listen-address='0.0.0.0:9090' --storage.tsdb.retention=15d"
詳細的參數與說明可以參考設定檔中的註解說明。
Prometheus 伺服器可以使用 systemctl 指令來操控:
# 查詢 Prometheus 伺服器狀態 systemctl status prometheus # 啟動 Prometheus 伺服器 sudo systemctl start prometheus # 重新啟動 Prometheus 伺服器 sudo systemctl restart prometheus # 停止 Prometheus 伺服器 sudo systemctl stop prometheus # 重新載入 Prometheus 伺服器 sudo systemctl reload prometheus
在負責發送告警的伺服器上,安裝 prometheus-alertmanager 套件:
# 安裝 prometheus 與 prometheus-alertmanager
sudo apt install prometheus-alertmanager
Alertmanager 伺服器通常可以跟 Prometheus 伺服器放在同一台機器上。
Alertmanager 伺服器的設定檔位於 /etc/default/prometheus-alertmanager,雖然可調整的參數不同,但設定方式跟 Prometheus 伺服器的設定檔類似,都是設定啟動伺服器時的指令參數。
Alertmanager 伺服器可以使用 systemctl 指令來操控:
# 查詢 Alertmanager 伺服器狀態 systemctl status prometheus-alertmanager # 啟動 Alertmanager 伺服器 sudo systemctl start prometheus-alertmanager # 重新啟動 Alertmanager 伺服器 sudo systemctl restart prometheus-alertmanager # 停止 Alertmanager 伺服器 sudo systemctl stop prometheus-alertmanager # 重新載入 Alertmanager 伺服器 sudo systemctl reload prometheus-alertmanager
在受監控的機器上安裝 prometheus-node-exporter 套件:
# 安裝 prometheus-node-exporter 套件
sudo apt install prometheus-node-exporter
Node Exporter 本身也是一個伺服器,其設定檔位於 /etc/default/prometheus-node-exporter,設定方式也都類似,在這個設定檔中可以調整 Node Exporter 要收集的系統資訊。
Node Exporter 伺服器可以使用 systemctl 指令來操控:
# 查詢 Node Exporter 伺服器狀態 systemctl status prometheus-node-exporter # 啟動 Node Exporter 伺服器 sudo systemctl start prometheus-node-exporter # 重新啟動 Node Exporter 伺服器 sudo systemctl restart prometheus-node-exporter # 停止 Node Exporter 伺服器 sudo systemctl stop prometheus-node-exporter # 重新載入 Node Exporter 伺服器 sudo systemctl reload prometheus-node-exporter
Prometheus 伺服器的預設設定檔路徑是 /etc/prometheus/prometheus.yml,在這個檔案中可以調整 Prometheus 伺服器的各種設定,此設定檔的語法採用 YAML,參數設定方式與說明可參考 Prometheus 官方網頁的說明或是官方的設定檔範例。以下是一個最簡單的設定檔範例:
# 預設參數 global: scrape_interval: 15s # 抓取監控資訊的間隔時間 evaluation_interval: 15s # 評判告警規則的間隔時間 # 將資料或告警轉送外部系統時附加的標籤資訊 external_labels: monitor: 'example' # Alertmanager 設定 alerting: alertmanagers: - static_configs: - targets: ['localhost:9093'] # Alertmanager 伺服器位址 # 載入告警規則,依據 evaluation_interval 設定的間隔時間定期評判告警 rule_files: - "first_rules.yml" - "second_rules.yml" - "my_rules/*.yml" # 載入目錄下所有 YAML 檔案 # 抓取監控資訊 scrape_configs: # 抓取 Prometheus 伺服器本身的資訊 - job_name: 'prometheus' # 覆蓋預設的設定值 scrape_interval: 5s # 抓取監控資訊的間隔時間 scrape_timeout: 5s # 評判告警規則的間隔時間 metrics_path: '/metrics' # metrics 路徑,預設為 '/metrics' scheme: 'http' # 傳輸協定,預設為 'http' static_configs: - targets: ['localhost:9090'] # 受監控機器的位址 # 抓取 Node Exporter 的資訊 - job_name: 'node' static_configs: - targets: ['localhost:9100'] # 受監控機器的位址
在 global 區塊中,可以設定各種參數的預設值,在後續的區塊中若沒有明確指定參數值,就會採用 global 中的設定值。
alerting 區塊則是連接 Alertmanager 的設定,這裡只有簡單指定 Alertmanager 伺服器位址而已。
rule_files 區塊可以引入自己定義的告警規則,讓 Prometheus 根據 evaluation_interval 參數所設定的間隔時間來定期評估告警規則,產生對應的告警訊息。告警規則我們會在後面的內容介紹如何撰寫,這裡在測試時可以暫時先將這幾行設定拿掉。
scrape_configs 區塊則是定義各個被監控的機器資訊,在 Prometheus 中每一個可被監控的個體稱為 instance,而多個相同功能的 instance 可以組成一個 job,而 job 與 instance 的資訊都寫在 scrape_configs 區塊中。這裡我們設定的監控資訊來源有兩個,一個是 Prometheus 伺服器本身的資訊,另一個則是自行安裝 Node Exporter 節點。
在設定 job 與 instance 的時候,若遇到連線相關的問題,可以使用 curl 等指令工具先測試各 instance 本身是否能正常提供 metrics:
# 測試 Prometheus 伺服器的 metrics curl http://localhost:9090/metrics # 測試 Node Exporter 伺服器的 metrics curl http://localhost:9100/metrics
正常來說各個 instance 的 metrics_path 路徑都要能正常傳回所有監控的資訊。
更改完 Prometheus 伺服器的設定之後,要重新載入 Prometheus 伺服器,讓設定生效:
# 重新載入 Prometheus 伺服器 sudo systemctl reload prometheus
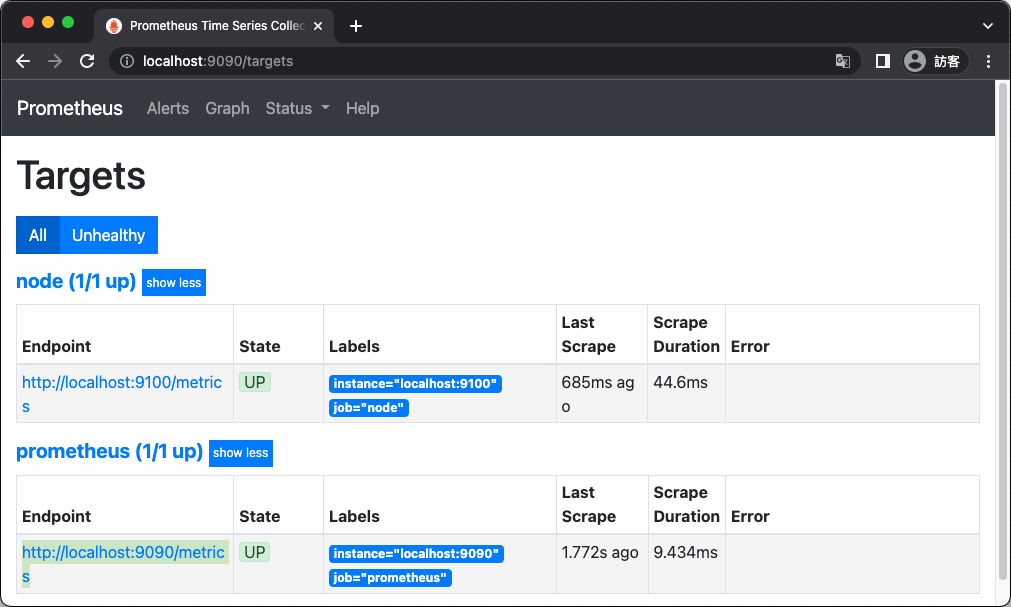
重新載入設定之後,正常來說以瀏覽器開啟 Prometheus 伺服器的 http://localhost:9090/ 就可以看到 Prometheus 伺服器的網頁操作介面,首先在主選單的「Status」中選擇「Targets」,查看目前 Prometheus 所設定好的監控資訊接收來源。
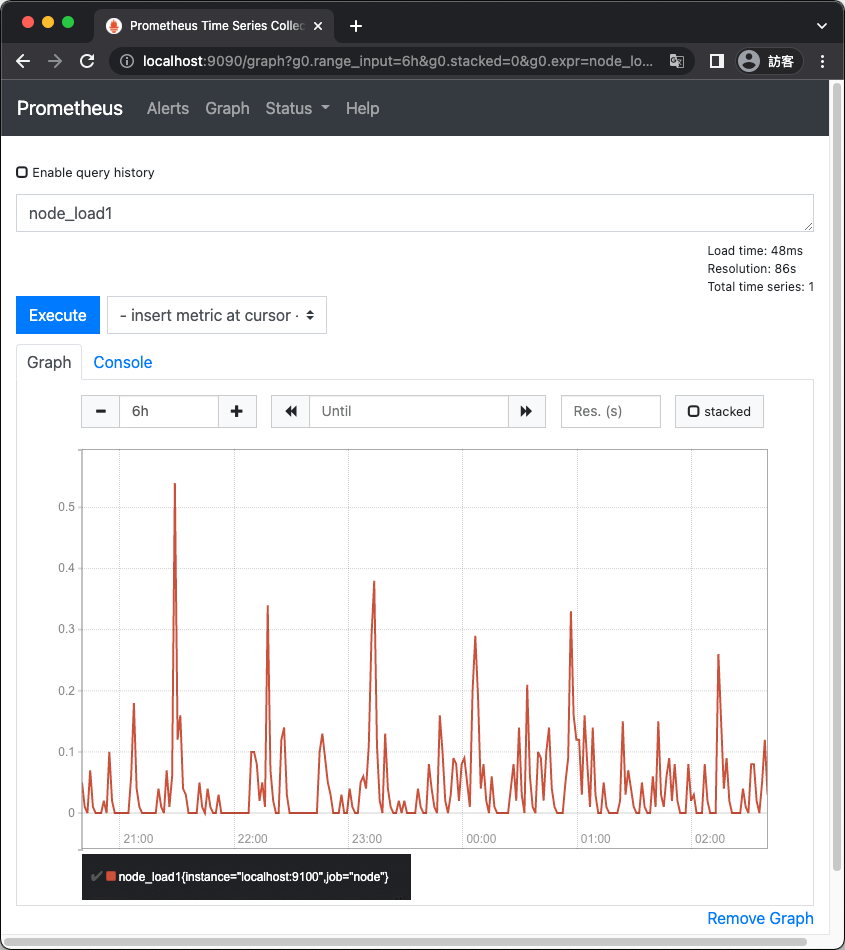
在 Prometheus 網頁介面 Graph 頁面中,可以透過 PromQL 語法查詢資料庫中的監控資訊,例如輸入 node_load1 就可以查詢受監控機器的一分鐘的負載量,以下是 node_load1{instance="localhost:9100",job="node"} 的圖形:
Grafana 是一個儀錶板工具,可用於顯示 Prometheus 所收集的各種監測資料,在 Ubuntu Linux 中可以透過 apt 來安裝 Grafana:
# 匯入開發者金鑰 wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add - # 加入 Grafana 套件庫 echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list # 安裝 Grafana sudo apt-get update sudo apt-get install grafana # 啟用 Grafana 服務 sudo systemctl daemon-reload sudo systemctl enable grafana-server
Grafana 伺服器同樣可以使用系統的 systemctl 指令來操控:
# 查詢 Grafana 伺服器狀態 systemctl status grafana-server # 啟動 Grafana 伺服器 sudo systemctl start grafana-server # 重新啟動 Grafana 伺服器 sudo systemctl restart grafana-server # 停止 Grafana 伺服器 sudo systemctl stop grafana-server # 重新載入 Grafana 伺服器 sudo systemctl reload grafana-server
安裝好 Grafana 之後,以瀏覽器開啟 http://localhost:3000/,預設的帳號為 admin,預設密碼也是 admin,登入之後會立即重新設定密碼。
登入 Grafana 之後,就可以看到 Grafana 的網頁介面,接著依據以下步驟設定 Prometheus 的資料來源與儀表板。
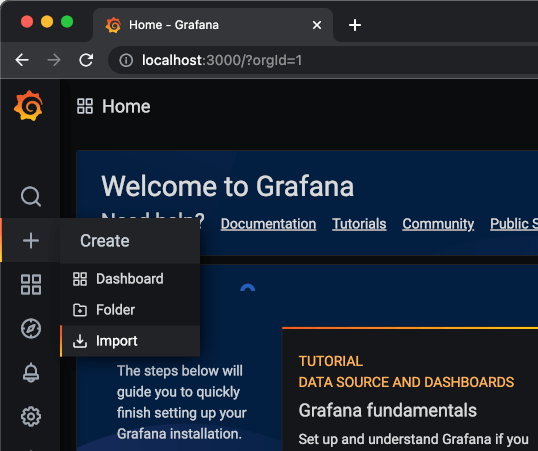
Step 1
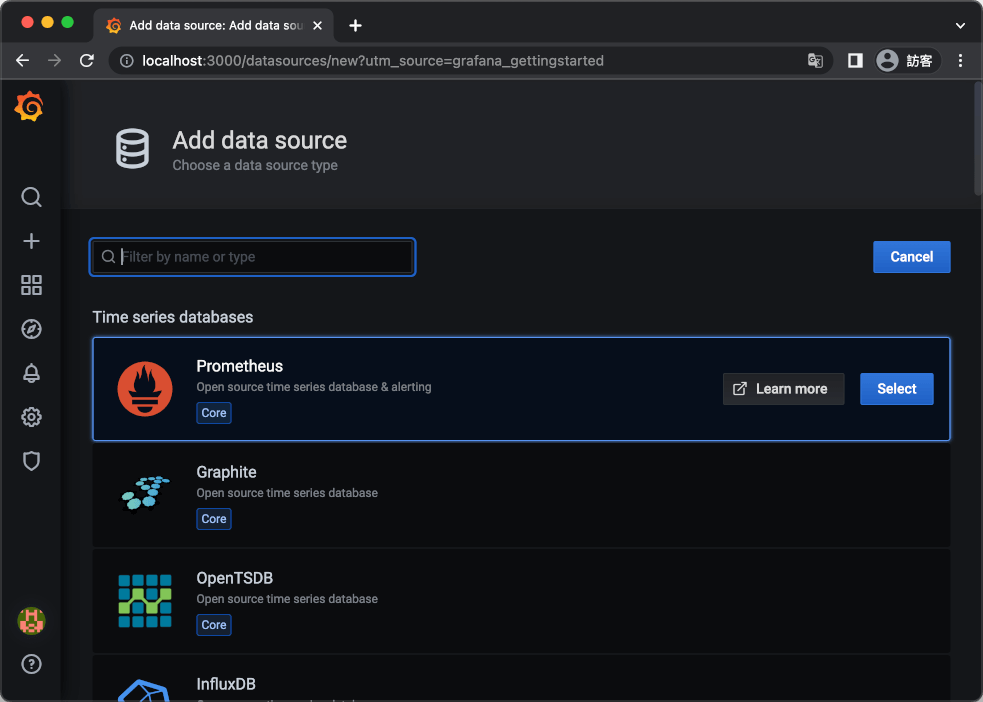
新增資料來源(data source),點選「Add your first data source」。
Step 2
在 Grafana 新增資料來源的頁面中,選擇「Prometheus」。
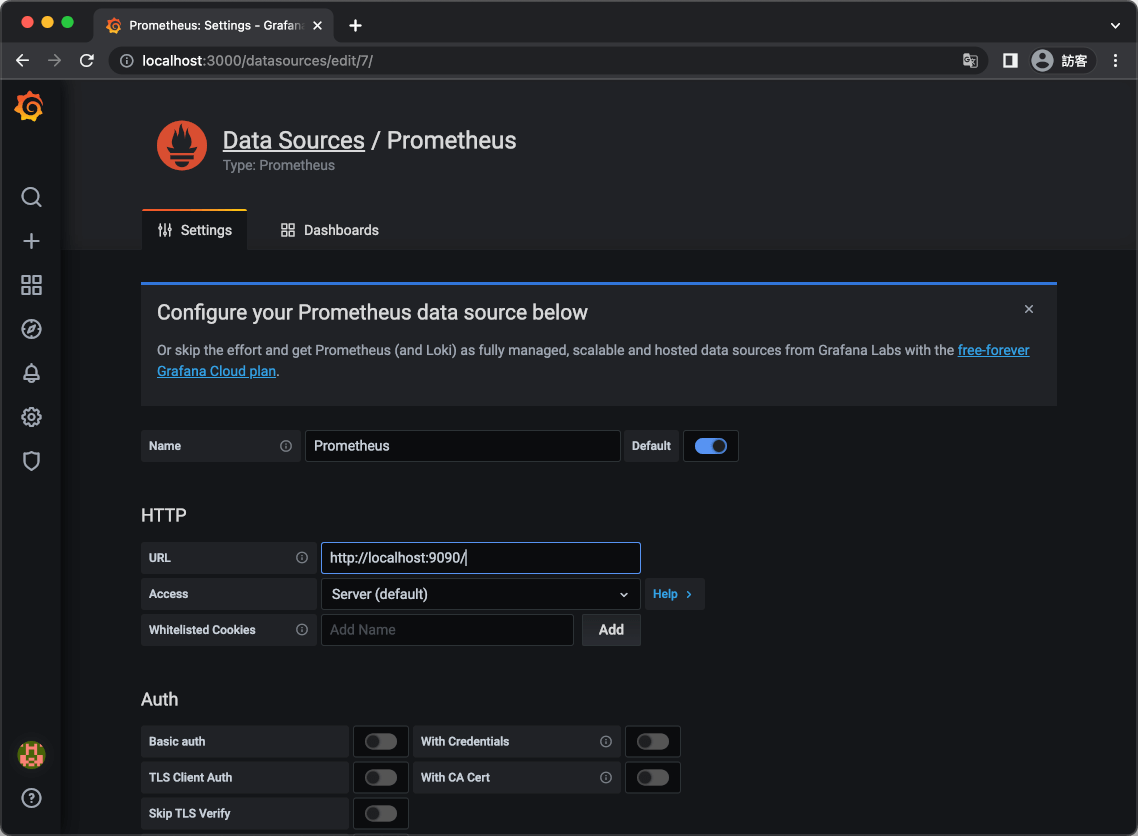
Step 3
設定 Prometheus 資料來源,在 URL 欄位填入 Prometheus 伺服器的位址,Prometheus 伺服器預設的連接埠是 9090,例如 http://localhost:9090/。
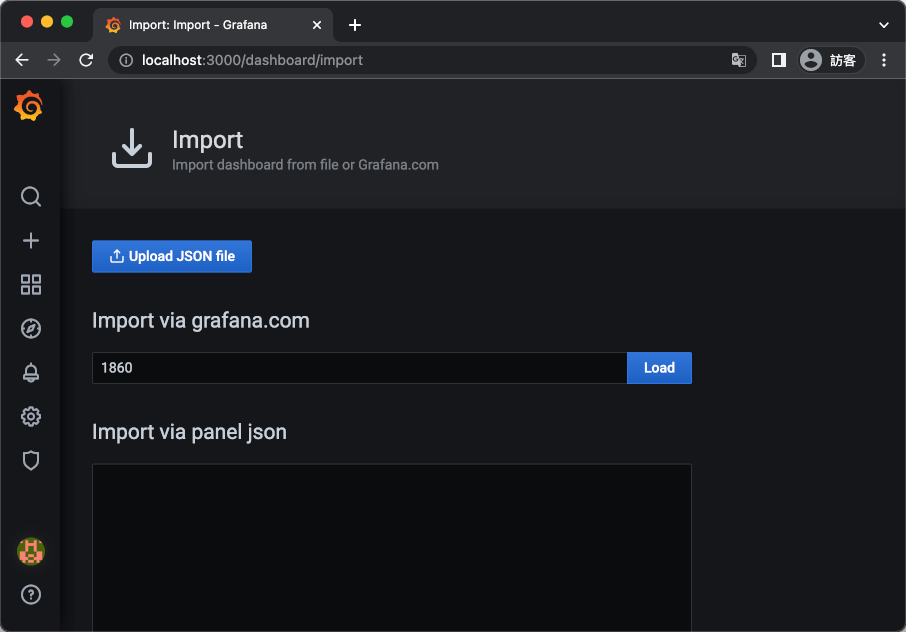
Step 4
接著選擇「Import」功能,匯入儀表板(dashboard)。
Step 5
在「Import via grafana.com」欄位中,填入 1860,匯入 Node Exporter Full 儀表板。
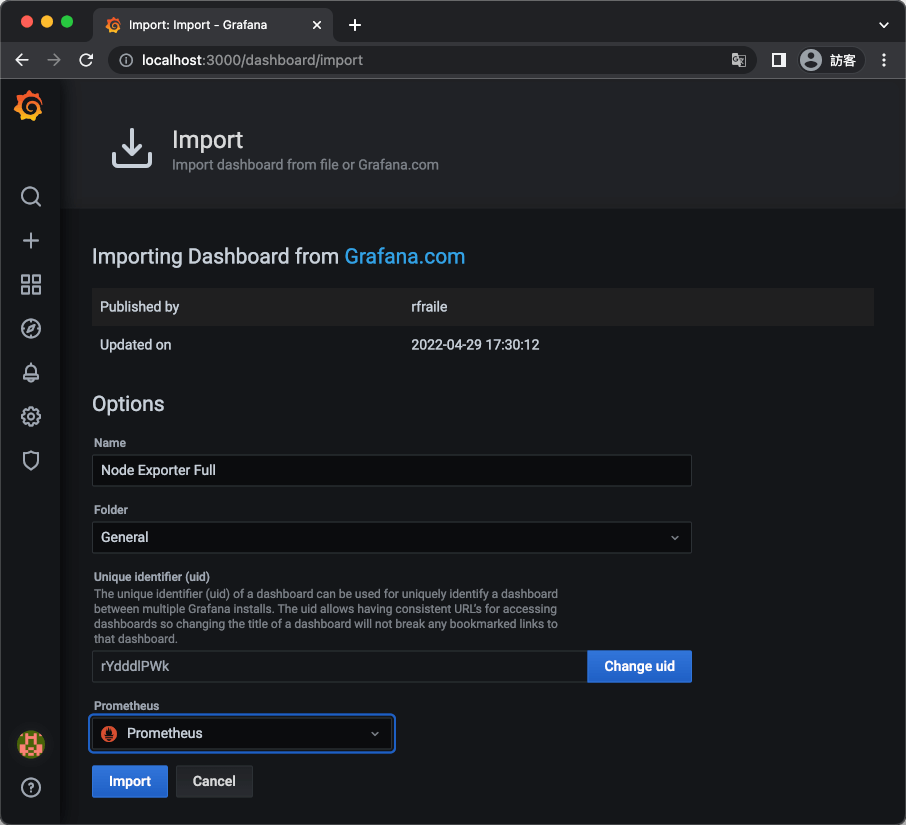
Step 6
選擇 Prometheus 資料來源,點選「Import」。
Step 7
選擇 Grafana 的儀表板,就可以看到各種監控資料了。
Prometheus 可以自訂告警的規則,在前面的 /etc/prometheus/prometheus.yml 設定檔中,我們有設定載入 first_rules.yml 與 second_rules.yml 兩個 YAML 設定檔,以及 my_rules 目錄下所有 YAML 檔案,在這些 YAML 檔案中都可以撰寫自己定義的告警規則。
假設我們要新增一個 CPU 高負載的告警規則,可以在 my_rules 目錄下新增一個 cpu.yml 檔案,設定 CPU 負載量超過 80% 的時候產生告警,設定檔內容如下:
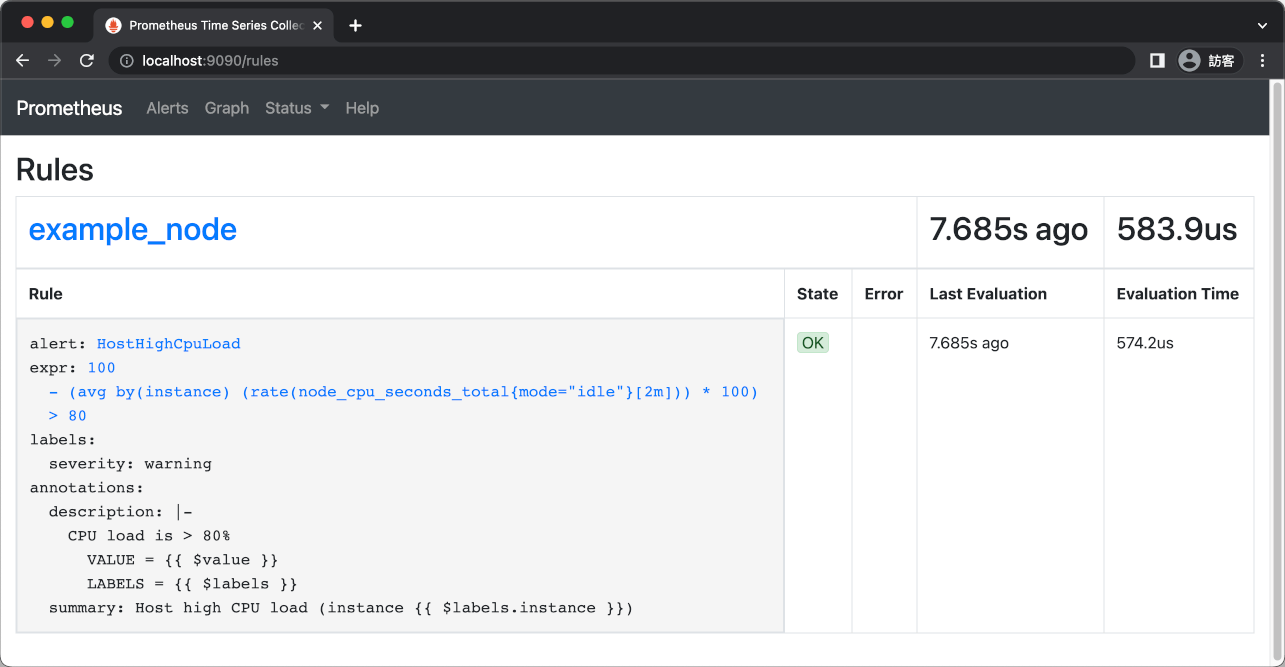
groups: - name: example_node rules: - alert: HostHighCpuLoad expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80 for: 0m labels: severity: warning annotations: summary: Host high CPU load (instance {{ $labels.instance }}) description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
在 Awesome Prometheus alerts 中有非常多常用的告警規則範例,建議可以從中選擇需要的設定,複製後再自行調整。
撰寫好告警規則檔之後,可以使用 promtool 工具來檢查語法是否正確:
# 檢查告警規則語法
promtool check rules cpu.yml
Checking cpu.yml SUCCESS: 1 rules found
設定好告警規則之後,重新啟動 Prometheus 伺服器:
# 重新啟動 Prometheus 伺服器 sudo systemctl restart prometheus
此時我們可以在 Prometheus 的 Rules 頁面中查詢目前設定的告警規則:
編輯 /etc/prometheus/alertmanager.yml 設定檔,參考 Prometheus 官方的文件說明,依據自己的需求設定告警訊息的遞送方式,最常見的就是透過 Email 發送告警訊息:
# 預設參數 global: # 郵件伺服器相關設定 smtp_smarthost: 'localhost:25' smtp_from: 'alertmanager@localhost' # smtp_auth_username: 'alertmanager' # smtp_auth_password: 'password' smtp_require_tls: false # 告警通知路由設定 route: # 告警通知的群組設定,合併相同的 alertname, cluster 與 service group_by: ['alertname', 'cluster', 'service'] # 告警群組訊息建立後的等待時間 group_wait: 30s # 相同群組,發送新告警訊息的間隔時間 group_interval: 5m # 重新發送相同告警訊息的間隔時間 repeat_interval: 3h # 預設收件者 receiver: admin-mails # 收件者設定 receivers: - name: 'admin-mails' email_configs: - to: 'root@localhost'
這裡的 smtp_require_tls 可以設定是否要使用 TLS 加密的 SMTP 連線,在初期開發與測試的階段,可以先設定為 false 會比較方便,在正式環境中再加入 TLS 加密功能。
更新 Alertmanager 的設定之後,重新啟動 Alertmanager 伺服器:
# 重新啟動 Alertmanager 伺服器 sudo systemctl restart prometheus-alertmanager
我們可以使用以下指令讓系統的 CPU 處於滿載的狀態,測試告警訊息是否會發送。
# 讓 CPU 處於滿載狀態
cat /dev/zero > /dev/null
若要測試更多的系統負載,可以參考 Linux 使用 Stress-ng 測試 CPU、記憶體、磁碟 I/O 滿載情況教學與範例。
當 CPU 負載量超過 80% 之後,就會出現告警,我們可以在 Prometheus 的 Alerts 頁面查詢目前出現的告警:
這時候 Prometheus 也會同時發送告警的 Email 通知信給我們設定的收件者。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}