介紹如何在 Python 中使用 auditok 模組,偵測並分割聲音資料中有訊號(有人講話等)的區段。
Python 的 auditok 模組是一個聲音活性檢測工具,可以偵測聲音資料中是否存在訊號,可以處理即時的音訊輸入(例如麥克風)或是各種聲音檔案。
auditok 模組auditok 模組可以透過 pip 安裝:
# 安裝 auditok 模組
pip install auditok
通常在分析聲音資料時,除了 auditok 之外,還會搭配一些其他的相關模組,所以建議一起安裝:
# 安裝相關模組
pip install pydub pyaudio tqdm matplotlib numpy
這裡我們從 zenodo 的網站上下載 Coughs: ESC-50 and FSDKaggle2018 咳嗽聲音資料,以這些資料做為示範。
引入 auditok 模組之後,使用 load() 函數載入 wav 聲音檔案:
import auditok # 載入 wav 聲音檔案 region = auditok.load("data/coughs/fd8121bc.wav")
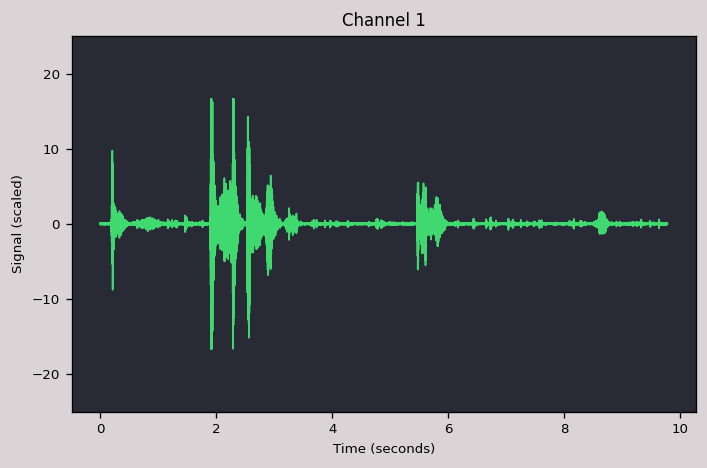
載入音訊之後,可以直接使用 plot() 函數繪製波形:
# 繪製波形圖
region.plot()
如果音訊的開頭有一些沒有用的訊號,可以使用 skip 指定跳過的秒數:
# 跳過開頭 2 秒的音訊 region = auditok.load("data/coughs/fd8121bc.wav", skip=2)
這樣就可以跳過前 2 秒的資料,從 2 秒之後開始讀取。
split 函數可以根據聲音的訊號強弱,偵測出聲音事件(例如是否有人在講話),並將各個聲音事件分割出來,這個函數是 auditok 模組中最重要的函數之一,其常用的參數與意義如下:
min_durmax_durmax_silencemax_silencedrop_trailing_silenceanalysis_windowlarge_fileTrue 或 False,若設定為 True 則可分批載入檔案,節省記憶體。energy_threshold50,能量值的計算方式可參考 auditok 的官方文件。若要將剛剛讀取出來的 region 音訊資料進行偵測並分割聲音事件,可以執行:
# 偵測並分割聲音事件 audio_regions = region.split( min_dur=0.2, # 聲音事件的最短長度 max_dur=4, # 聲音事件的最長長度 max_silence=0.3, # 聲音事件中無訊號最長長度 energy_threshold=55 # 偵測聲音事件的能量門檻值 )
將聲音事件分割出來之後,可以透過迴圈逐一處理每一段音訊,或是將每一段音訊儲存成個別的聲音檔案:
# 輸出分割聲音事件結果 for i, r in enumerate(audio_regions): # 輸出每段分割音訊的起始與結束時間點 print("Region {i}: {r.meta.start:.3f}s -- {r.meta.end:.3f}s".format(i=i, r=r)) # 撥放每段分割音訊 # r.play(progress_bar=True) # 儲存每段分割音訊 filename = r.save("region_{meta.start:.3f}-{meta.end:.3f}.wav") print("儲存為:{}".format(filename))
Region 0: 0.150s -- 0.700s 儲存為:region_0.150-0.700.wav Region 1: 1.450s -- 1.800s 儲存為:region_1.450-1.800.wav Region 2: 1.900s -- 3.650s 儲存為:region_1.900-3.650.wav Region 3: 5.450s -- 6.250s 儲存為:region_5.450-6.250.wav Region 4: 8.600s -- 9.000s 儲存為:region_8.600-9.000.wav
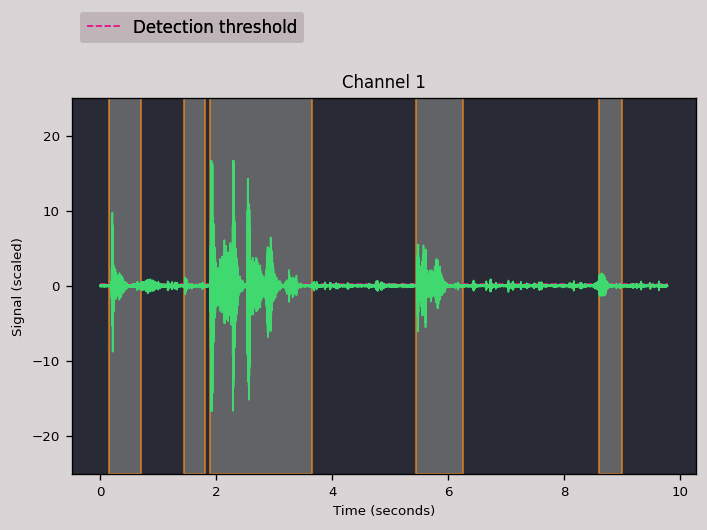
如果需要透過圖形查看聲音事件的偵測結果,可以將 split() 改為 split_and_plot() 函數,參數用法都相同,只是替換函數名稱而已:
# 偵測並分割聲音事件,同時繪圖 audio_regions = region.split_and_plot( min_dur=0.2, # 聲音事件的最短長度 max_dur=4, # 聲音事件的最長長度 max_silence=0.3, # 聲音事件中無訊號最長長度 energy_threshold=55 # 偵測聲音事件的門檻值 )
這樣就會自動畫出聲音事件的偵測結果。
如果要處理大型的聲音檔案,可以改用指定檔案路徑的方式來呼叫 split() 函數,並將 large_file 參數指定為 True,這樣可以讓 auditok 不要一次將整個檔案載入,改以分段批次處理的方式,以節省所需的記憶體:
# 處理大型檔案 audio_regions = auditok.split( "large_file.wav", # 大型檔案 min_dur=0.2, # 聲音事件的最短長度 max_dur=4, # 聲音事件的最長長度 max_silence=0.3, # 聲音事件中無訊號最長長度 energy_threshold=55,# 偵測聲音事件的能量門檻值 large_file=True # 處理大型檔案 )
auditok 指令工具auditok 除了 Python 的模組之外,也同時提供了指令工具,基本概念與參數用法都跟 split() 函數類似:
# 使用 auditok 指令工具偵測聲音事件 auditok --min-duration 0.2 --max-duration 4 --max-silence 0.3 \ --energy-threshold 55 data/coughs/fd8121bc.wav
1 0.190 0.710 2 0.790 1.220 3 1.460 1.790 4 1.900 3.690 5 4.760 5.070 6 5.460 6.250 7 8.590 9.020
auditok 指令預設會輸出每個聲音事件的起始與結束時間點。
我們也可以透過 --save-detections-as 儲存每段偵測到的聲音事件音訊:
# 儲存每段偵測到的聲音事件音訊 auditok --min-duration 0.2 --max-duration 4 --max-silence 0.3 \ --energy-threshold 55 --save-detections-as "{id}_{start}_{end}.wav" \ data/coughs/fd8121bc.wav
這樣就會將每段偵測到的聲音事件音訊,依據編號、起始與結束時間來儲存為不同的聲音檔案。
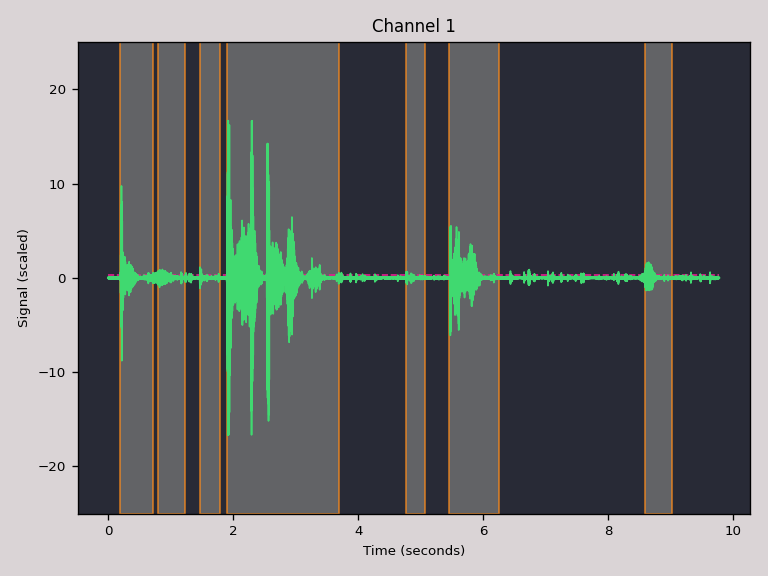
auditok 指令也可以使用 --plot 參數將聲音事件偵測結果畫出來,並以 --save-image 參數輸出的圖檔:
# 偵測聲音事件與繪圖 auditok --min-duration 0.2 --max-duration 4 --max-silence 0.3 \ --energy-threshold 55 --plot --save-image "plot.png" \ data/coughs/fd8121bc.wav
auditok 指令也可以從標準輸入讀取聲音資料,例如:
# 從標準輸入讀取聲音資料 rec -q -t raw -r 16000 -c 1 -b 16 -e signed - | auditok - -r 16000 -w 2 -c 1
{kind=link}
{kind=link}
{kind=link}