介紹如何在 Python 中處理 Excel 與 NumPy 或 Pandas 之間的資料格式轉換。
許多表格類型的資料都會以 Excel 格式來儲存,而在 Python 中若要處理表格類型的資料,最常用的就是 NumPy 與 Pandas 兩套函式庫,以下是處理 Excel 表格與 NumPy 與 Pandas 資料格式之間的轉換的基本範例。
若要將 NumPy 的數值矩陣資料,儲存於 Excel 工作表中,可以將 NumPy 陣列轉為串列(list)之後,再透過 openpyxl 模組將資料寫入 Excel 工作表中,以下是簡單的操作範例:
import numpy import openpyxl # 建立 NumPy 陣列 myArr = numpy.array([[1, 2, 3], [4, 5, 6]]) # 建立 Excel 活頁簿 wb = openpyxl.Workbook() # 取得作用中的工作表 ws = wb.active # 設定工作表名稱 ws.title = "NumPy_Arr" # 將 NumPy 陣列寫入 Excel 工作表 for x in myArr: ws.append(x.tolist()) # 儲存 Excel 活頁簿至檔案 wb.save(filename='test.xlsx')
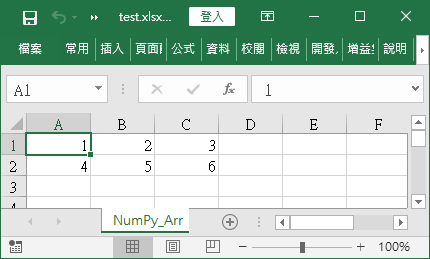
上面這個範例執行之後,會建立一個 test.xlsx 檔案,其內容如下:
若要反過來將 Excel 工作表的數值矩陣讀取至 Python 的 NumPy 陣列中,可以參考以下範例:
import numpy import openpyxl # 讀取 Excel 活頁簿 wb = openpyxl.load_workbook('test.xlsx') # 取得作用中的工作表 ws = wb.active # 將 Excel 工作表轉為串列 myList = [row for row in ws.values] # 將串列轉為 NumPy 陣列 myArr = numpy.array(myList) # 輸出 NumPy 陣列 print(myArr)
[[1 2 3] [4 5 6]]
若要將 Pandas 的 dataframe 資料表儲存於 Excel 工作表中,可以使用 Pandas 內建的 to_excel 函數來處理,以下是簡單的操作範例:
import pandas # 建立 Pandas 資料表 d = {'col1': [1, 2, 3], 'col2': [4, 5, 6]} df = pandas.DataFrame(data=d) # 將 Pandas 資料表寫入 Excel 檔案 df.to_excel("test2.xlsx")
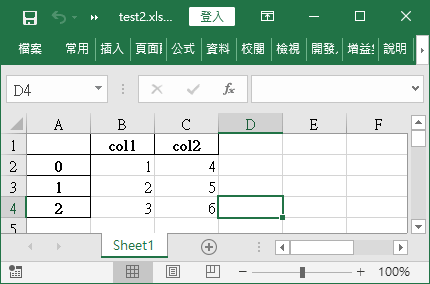
輸出的 Excel 檔案會像這樣:
若要讀取 Excel 檔案並轉為 Pandas 資料表,可以使用 Pandas 的 read_excel 函數,並搭配 openpyxl 引擎來讀取 Excel 檔案:
import pandas # 讀取 Excel 檔案轉為 Pandas 資料表 df = pandas.read_excel("test2.xlsx", index_col=0, engine='openpyxl') print(df)
col1 col2 0 1 4 1 2 5 2 3 6
由於這裡讀取的 Excel 檔案中,第一欄是標示所引用的欄位,所以要加上 index_col 參數來指定索引欄位,若 Excel 檔案中沒有所以欄位,則可移除此參數。
另外亦可使用 openpyxl 來處理 Pandas 與 Excel 檔案的轉換,但這種方式比較不直接,詳細用法可參考 openpyxl 的說明文件。
{kind=link}
{kind=link}