介紹如何使用 PyTorch 實作遷移式學習,以 ResNet18 預訓練模型訓練可分類 MNIST 數字影像的模型。
MNIST 資料集是一個包含 0 到 9 手寫數字的影像資料集,其影像格式為灰階影像,而 ResNet18 模型所輸入的影像格式卻為 RGB 的影像,為了讓 MNIST 的影像可以套用 ResNet18 模型,在資料載入時我們使用一個自訂的轉換函數,將灰階影像轉為 RGB 影像,轉換的方式就是把灰階影像的單一 channel 複製成 RGB 影像的三個 channel。
import torch import torch.nn as nn from torchvision import datasets, models, transforms, utils import matplotlib.pyplot as plt # 資料轉換函數 transform = transforms.Compose([ transforms.ToTensor(), # 轉為 Tensor transforms.Lambda(lambda x: x.repeat(3, 1, 1)), # 灰階轉為 RGB ])
套用影像格式轉換函數,建立 Dataset,自動下載 MNIST 資料集,並顯示訓練資料集與測試資料集的資料數量:
# 建立 MNIST 的 Dataset mnist_train = datasets.MNIST( root='./data', # 資料放置路徑 train=True, # 訓練資料集 download=True, # 自動下載 transform=transform # 轉換函數 ) mnist_test = datasets.MNIST( root='./data', # 資料放置路徑 train=False, # 測試資料集 download=True, # 自動下載 transform=transform # 轉換函數 ) print("訓練資料集數量:", len(mnist_train)) print("測試資料集數量:", len(mnist_test))
訓練資料集數量: 60000 測試資料集數量: 10000
將 Dataset 以 DataLoader 包裝成一個 iterable,提供自動批次載入(batching)、隨機取樣(sampling)、亂數排序(shuffling)、平行化載入(multiprocess data loading)功能。
此處將 batch_size 設定為 256,代表 DataLoader 在疊代時每次載入 256 筆資料與標註。
# 批次載入資料筆數 batch_size = 256 # 建立 DataLoader train_loader = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size) test_loader = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size)
測試以 DataLoader 載入一個 batch 的資料(也就是 256 張數字圖片),並將所有圖片拼成一張大圖,顯示出來:
# 測試以 DataLoader 載入資料 for X, y in test_loader: print("Shape of X [N, C, H, W]: ", X.shape) print("Shape of y: ", y.shape, y.dtype) # 顯示 MNIST 數字圖片 img = utils.make_grid(X, nrow=16) plt.imshow(img.numpy().transpose((1, 2, 0))) plt.show() break
Shape of X [N, C, H, W]: torch.Size([256, 3, 28, 28]) Shape of y: torch.Size([256]) torch.int64
在採用 ResNet18 預訓練模型之前,先檢視一下 ResNet18 模型的結構:
# 檢視 ResNet18 模型結構 net = models.resnet18() print(net)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
在原始的 ResNet18 網路結構中,最後一層 fc 的輸出數量是 1000,而在 MNIST 資料集中只需要 10 個輸出(數字 0 到 9),所以在使用 ResNet18 預訓練模型時,需要將 fc 層的輸出數量修改一下。
# 定義類神經網路模型 class MNIST_ResNet18(nn.Module): def __init__(self): super(MNIST_ResNet18, self).__init__() # 載入 ResNet18 類神經網路結構 self.model = models.resnet18(pretrained=True) # 鎖定 ResNet18 預訓練模型參數 #for param in self.model.parameters(): # param.requires_grad = False # 修改輸出層輸出數量 self.model.fc = nn.Linear(512, 10) def forward(self, x): logits = self.model(x) return logits
這裡我們可以選擇是否要鎖定 ResNet18 預訓練模型的原始參數,如果將這些原始參數鎖定,在訓練模型時就不會更動這些參數,可以加速訓練的過程。
在 PyTorch 中我們可以透過 torch.cuda.is_available() 函數來判斷是否有 GPU 環境可以使用,若有 GPU 環境則可使用 GPU 加速運算,否則就使用普通的 CPU:
# 若 CUDA 環境可用,則使用 GPU 計算,否則使用 CPU device = "cuda" if torch.cuda.is_available() else "cpu" print(f"Using {device} device")
Using cuda device
建立類神經網路模型,並放置於 GPU 或 CPU 上:
# 建立類神經網路模型,並放置於 GPU 或 CPU 上 model = MNIST_ResNet18().to(device) print(model)
MNIST_ResNet18(
(model): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
)
定義損失函數(loss function)與學習優化器(optimizer):
# 損失函數 loss_fn = nn.CrossEntropyLoss() # 學習優化器 optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
定義訓練模型用的函數:
# 訓練模型 def train(dataloader, model, loss_fn, optimizer): # 資料總筆數 size = len(dataloader.dataset) # 將模型設定為訓練模式 model.train() # 批次讀取資料進行訓練 for batch, (X, y) in enumerate(dataloader): # 將資料放置於 GPU 或 CPU X, y = X.to(device), y.to(device) pred = model(X) # 計算預測值 loss = loss_fn(pred, y) # 計算損失值(loss) optimizer.zero_grad() # 重設參數梯度(gradient) loss.backward() # 反向傳播(backpropagation) optimizer.step() # 更新參數 # 輸出訓練過程資訊 if batch % 100 == 0: loss, current = loss.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
定義測試模型用的函數:
# 測試模型 def test(dataloader, model, loss_fn): # 資料總筆數 size = len(dataloader.dataset) # 批次數量 num_batches = len(dataloader) # 將模型設定為驗證模式 model.eval() # 初始化數值 test_loss, correct = 0, 0 # 驗證模型準確度 with torch.no_grad(): # 不要計算參數梯度 for X, y in dataloader: # 將資料放置於 GPU 或 CPU X, y = X.to(device), y.to(device) # 計算預測值 pred = model(X) # 計算損失值的加總值 test_loss += loss_fn(pred, y).item() # 計算預測正確數量的加總值 correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 計算平均損失值與正確率 test_loss /= num_batches correct /= size print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
設定 epochs 數,開始訓練模型:
# 設定 epochs 數 epochs = 6 # 開始訓練模型 for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train(train_dataloader, model, loss_fn, optimizer) test(test_dataloader, model, loss_fn) print("完成!")
Epoch 1 ------------------------------- loss: 2.585408 [ 0/60000] loss: 0.076585 [25600/60000] loss: 0.089134 [51200/60000] Test Error: Accuracy: 98.1%, Avg loss: 0.059058 Epoch 2 ------------------------------- loss: 0.079516 [ 0/60000] loss: 0.015147 [25600/60000] loss: 0.041219 [51200/60000] Test Error: Accuracy: 98.6%, Avg loss: 0.044869 Epoch 3 ------------------------------- loss: 0.038047 [ 0/60000] loss: 0.005276 [25600/60000] loss: 0.024100 [51200/60000] Test Error: Accuracy: 98.8%, Avg loss: 0.041534 Epoch 4 ------------------------------- loss: 0.021060 [ 0/60000] loss: 0.003269 [25600/60000] loss: 0.015252 [51200/60000] Test Error: Accuracy: 98.8%, Avg loss: 0.039633 Epoch 5 ------------------------------- loss: 0.012474 [ 0/60000] loss: 0.002225 [25600/60000] loss: 0.008019 [51200/60000] Test Error: Accuracy: 98.9%, Avg loss: 0.039098 Epoch 6 ------------------------------- loss: 0.008820 [ 0/60000] loss: 0.001630 [25600/60000] loss: 0.004334 [51200/60000] Test Error: Accuracy: 98.9%, Avg loss: 0.038967 完成!
經過 6 個 epochs 的訓練,模型準確度達到 98.9%。
從測試資料集中取得一張圖片,以模型進行預測:
with torch.no_grad(): # 取得一張測試圖片 index = 256 # 圖片索引編號 image, true_target = mnist_test[index] # 取得圖片與標註 image = torch.unsqueeze(image, 0) # 多增加一個維度,轉為 batch 形式 # 將資料放置於 GPU 或 CPU image = image.to(device) # 以模型進行預測 prediction = model(image) # 整理預測結果 predicted_class = prediction.argmax() # 轉為 NumPy 影像(繪圖用) np_image = image[0].cpu().numpy().transpose((1, 2, 0)) # 顯示預測結果 plt.imshow(np_image, cmap='gray') plt.title(f'Predicted: {predicted_class} / True Target: {true_target}') plt.show()
{kind=link}
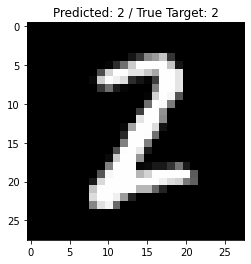{kind=link}