介紹如何使用 PyTorch 架構的 YOLOv5 預訓練模型,自行訓練物件偵測模型,用於辨識雞蛋。
安裝 Python 的 venc 套件之後,建立一個 YOLOv5 專用的 Python 虛擬環境:
# 安裝 Python 的 venv 套件 apt install python3.8-venv # 建立 Python 虛擬環境 yolov5env python3 -m venv yolov5env
載入 Python 虛擬環境 yolov5env:
# 載入 Python 虛擬環境 yolov5env
source yolov5env/bin/activate
下載 YOLOv5 原始碼,並在 Python 虛擬環境之下安裝 YOLOv5 所需要的各種 Python 套件:
# 下載 YOLOv5 原始碼 git clone https://github.com/ultralytics/yolov5 # 安裝 yolov5 所需環境 cd yolov5 pip install -r requirements.txt
detect.py 指令稿在 YOLOv5 的原始碼中,有附帶一個偵測物件用的 Python 指令稿 detect.py,可以使用指定的 YOLOv5 模型來進行物件偵測,例如拿官方的 zidane.jpg 圖檔進行物件偵測:
# 以 YOLOv5 模型偵測物件 python3 detect.py --source zidane.jpg
detect: weights=yolov5s.pt, source=https://ultralytics.com/images/zidane.jpg, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False Found https://ultralytics.com/images/zidane.jpg locally at zidane.jpg YOLOv5 🚀 v6.1-40-gb0ba101 torch 1.11.0+cu102 CPU Fusing layers... Model Summary: 213 layers, 7225885 parameters, 0 gradients image 1/1 /home/ubuntu/yolov5/zidane.jpg: 384x640 2 persons, 2 ties, Done. (0.121s) Speed: 5.9ms pre-process, 120.6ms inference, 1.6ms NMS per image at shape (1, 3, 640, 640) Results saved to runs/detect/exp
其中 --source 參數可以用來指定影像來源,支援的格式非常多,包含圖片檔案(jpg、png)、影片檔案(mp4)、包含圖片的目錄、YouTube 網址、RTSP 串流位址等,而偵測結果預設會擺放在 runs/detect/exp 目錄之下,以下是偵測的結果。
YOLOv5 實際上又依據模型複雜度分為 yolov5n、yolov5s、yolov5m、yolov5l、yolov5x,我們可以使用 --weight 參數來指定要採用的模型,例如使用 yolov5n:
# 以 YOLOv5 模型偵測物件 python3 detect.py --source zidane.jpg --weight yolov5n.pt
detect.py 指令稿還有支援其他相當多的參數,可以使用 --help 查詢:
# 查詢參數用法 python3 detect.py --help
除了使用既有的指令稿之外,我們也可以自行撰寫 Python 指令稿來使用 YOLOv5 模型偵測物件:
import torch # 從 PyTorch Hub 下載 YOLOv5s 預訓練模型,可選用的模型有 yolov5s, yolov5m, yolov5x 等 model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # 影像來源,支援檔案、路徑、PIL、OpenCV, NumPy, list 等 img = 'https://ultralytics.com/images/zidane.jpg' # 進行物件偵測 results = model(img) # 顯示結果摘要 results.print()
image 1/1: 720x1280 2 persons, 2 ties Speed: 1003.3ms pre-process, 130.5ms inference, 2.0ms NMS per image at shape (1, 3, 384, 640)
偵測出物件之後,可以顯示或儲存結果圖片:
# 顯示結果圖片 results.show() # 儲存結果圖片 results.save()
亦可顯示所有偵測到的物件列表,包含位置、信心(confidence)、類別編號與名稱:
# 顯示物件列表 results.pandas().xyxy[0]
xmin ymin xmax ymax confidence class name 0 743.290466 48.343628 1141.756592 720.000000 0.879861 0 person 1 441.989624 437.336731 496.585083 710.036194 0.675119 27 tie 2 123.051208 193.238037 714.690491 719.771301 0.666693 0 person 3 978.989807 313.579498 1025.302856 415.526215 0.261517 27 tie
若想要針對自己的資料,訓練出自己的 YOLO 模型,可以先準備好標註的圖片之後,再用預訓練的 YOLO 模型,進行遷移式學習(transfer learning)。
若要自己標注圖片,可以使用 LabelImg 這個開放原始碼的工具,此工具是以 Python 所開發的,可以用 pip3 安裝:
# 安裝 labelImg 圖片標注工具
pip3 install labelImg
安裝好之後,執行 labelImg:
# 執行 labelImg 圖片標注工具
labelImg
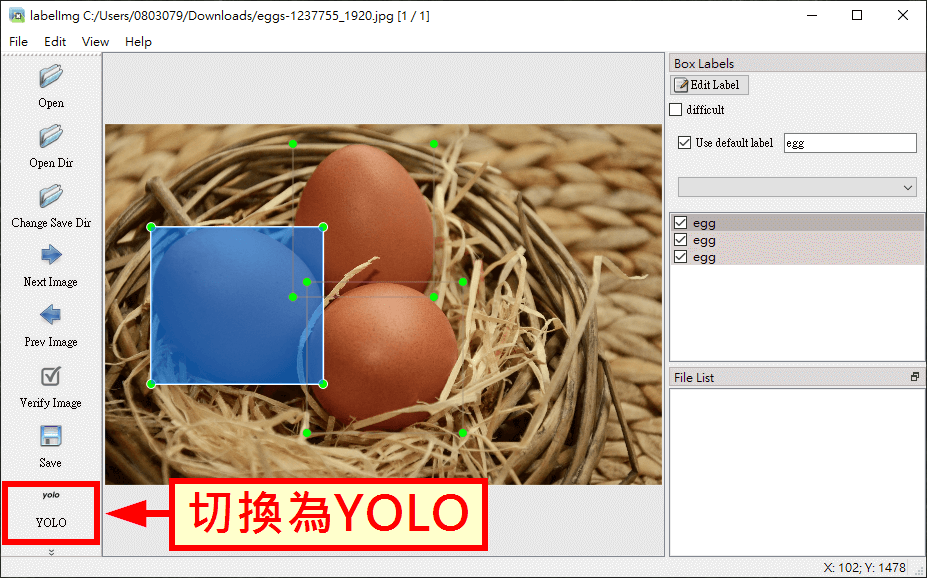
開啟 labelImg 標註工具之後,就可以用滑鼠框出圖片中的物件,並設定每個物件的類別,而在標註完成之後,在存檔之前記得要將儲存格式切換為 YOLO,儲存成訓練 YOLO 模型時可以直接使用的文字檔。
儲存標註資訊的文字檔時,要跟原來的圖片檔案名稱相同,只不過副檔名要改為 .txt,labelImg 預設的檔案名稱就是按照這樣的規則來命名的,所以就使用預設的檔案名稱即可,不要隨意更改,這樣之後在整理資料時會比較方便。
YOLO 的標註格式是普通文字檔,每一行代表一個標註物件,格式為 class x_center y_center width height,各欄位以空白分隔,意義如下:
class:類別 ID。x_center:中心點 X 座標(標準化)。y_center:中心點 Y 座標(標準化)。width:方框寬度(標準化)。height:方框高度(標準化)。以下是一個 YOLO 標註範例:
0 0.236719 0.502814 0.308854 0.434887 0 0.463542 0.266881 0.253125 0.424437 0 0.502083 0.646704 0.280208 0.418810
將所有的圖片標註好之後,參考 coco128 資料集的目錄結構,將自己的資料也依照同樣的目錄結構存放,類似像這樣:
eggs
├── images
│ └── train
│ ├── egg0.png
│ ├── egg1.png
│ └── egg2.png
└── labels
└── train
├── egg0.txt
├── egg1.txt
└── egg2.txt
YOLOv5 訓練程式在讀取圖檔所對應的標註檔案時,會將圖檔路徑中最後一個 images 替換為 labels,然後在這個路徑中尋找對應的標註檔案。
這裡我們只是舉例來說明圖片與標註檔案的目錄結構,實際上不會只用三筆資料就進行模型訓練,依照 YOLOv5 官方網頁上的建議,每個類別最好收集到 1500 張影像,並包含 10000 個標註物件。
接著為自己的資料集準備一個給訓練程式用的 eggs.yaml 設定檔,內容如下:
# 設定圖檔路徑 path: ../datasets/eggs # 資料根目錄 train: images/train # 訓練用資料集(相對於 path) val: images/train # 驗證用資料集(相對於 path) test: # 測試用資料集(相對於 path,可省略) # 物件類別設定 nc: 1 # 類別數量 names: ['egg'] # 類別名稱
其他資料集的 YAML 設定檔,可以從 YOLOv5 原始碼的 data 目錄中查看。
準備好標註資料與設定檔之後,執行 YOLOv5 原始碼中附帶的模型訓練指令稿:
# 進行 YOLOv5s 模型訓練 python train.py --img-size 640 --batch 16 --epochs 500 \ --data eggs.yaml --weights yolov5s.pt
這裡的 --img-size 可以指定影像的大小,對於偵測比較小的物件時,可以加大影像的大小,預設的影像大小為 640;--weights 則可用來指定預訓練的模型。
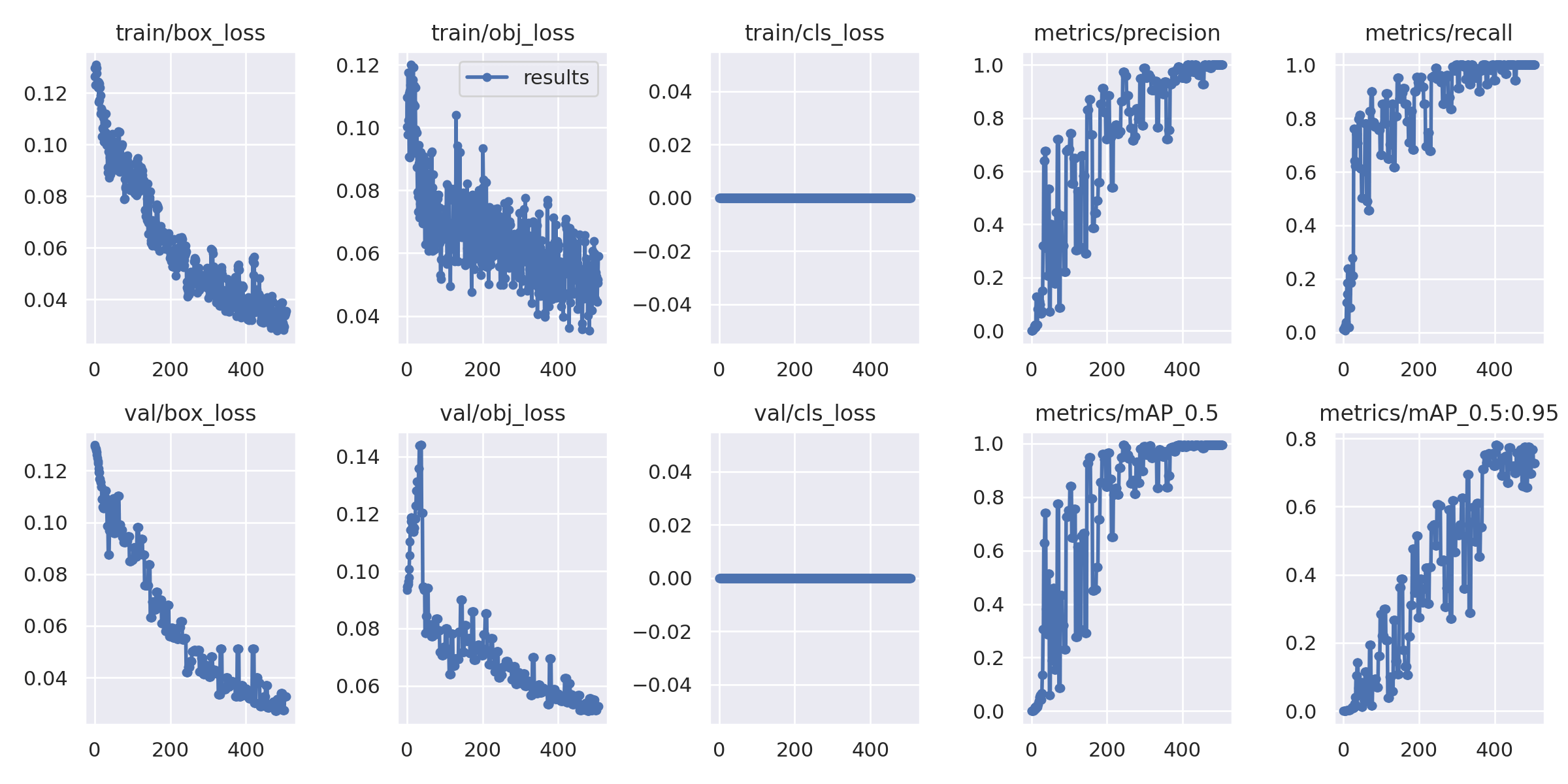
訓練完成之後,新的模型與各種訓練過程的資訊都會放在 runs/train/exp 目錄中,其中 result.png 可以查看模型的收斂狀況,如果模型收斂的情況不理想,可能就要考慮調整參數並重新訓練。
而在 runs/train/exp/weights 目錄中存放了最佳的模型參數 best.pt 以及訓練到最後的模型參數 last.pt,通常我們會使用 best.pt 這個最佳的模型參數來做後續的預測。
自己訓練出來的 YOLO 模型也可以直接套用 detect.py 指令稿進行預測:
# 使用自行訓練的 YOLO 模型進行預測 python detect.py --weight runs/train/exp/weights/best.pt \ --source eggs-test.jpg --iou-thres 0.3 --conf-thres 0.5
這裡的 --iou-thres 是設定 IoU 門檻值,而 --conf-thres 則是設定信心門檻值,這兩個值會直接影響物件偵測的結果,偵測的結果同樣會放在 runs/detect/exp 目錄之下。
自行訓練的 YOLOv5 模型,也可以用於自行撰寫的 Python 指令稿中,使用方式與前述標準的 YOLOv5 模型類似:
import torch # 載入自行訓練的 YOLOv5 模型 model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt') # 影像來源 img = 'eggs-test.jpg' # 設定 IoU 門檻值 model.iou = 0.3 # 設定信心門檻值 model.conf = 0.5 # 進行物件偵測 results = model(img) # 顯示結果摘要 results.print()
image 1/1: 1440x1920 12 eggs Speed: 49.7ms pre-process, 100.1ms inference, 2.0ms NMS per image at shape (1, 3, 480, 640)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}