使用 R 根據連續型的資料,估計機率分佈的參數,並且檢定模型的適合度,找出母體的機率分佈。
資料分析者在取得資料之後,通常都會想知道這些資料來自於什麼樣的機率分佈,在這篇教學中我們將使用 R 來解決這個問題。
首先我們隨機產生一些 Gamma 分佈的資料,並加上一些常態分佈的雜訊,模擬測量上的隨機誤差。
# 設定亂數種子 set.seed(3) # 產生的樣本數 N = 1000 # 產生 Gamma 分佈的樣本 x <- rgamma(N, shape = 10, scale = 3) # 加上常態分佈的誤差 x <- x + rnorm(N, mean = 0, sd = 0.1)
一般來說,尋找資料機率分佈的步驟,大致上可以分為四個步驟:
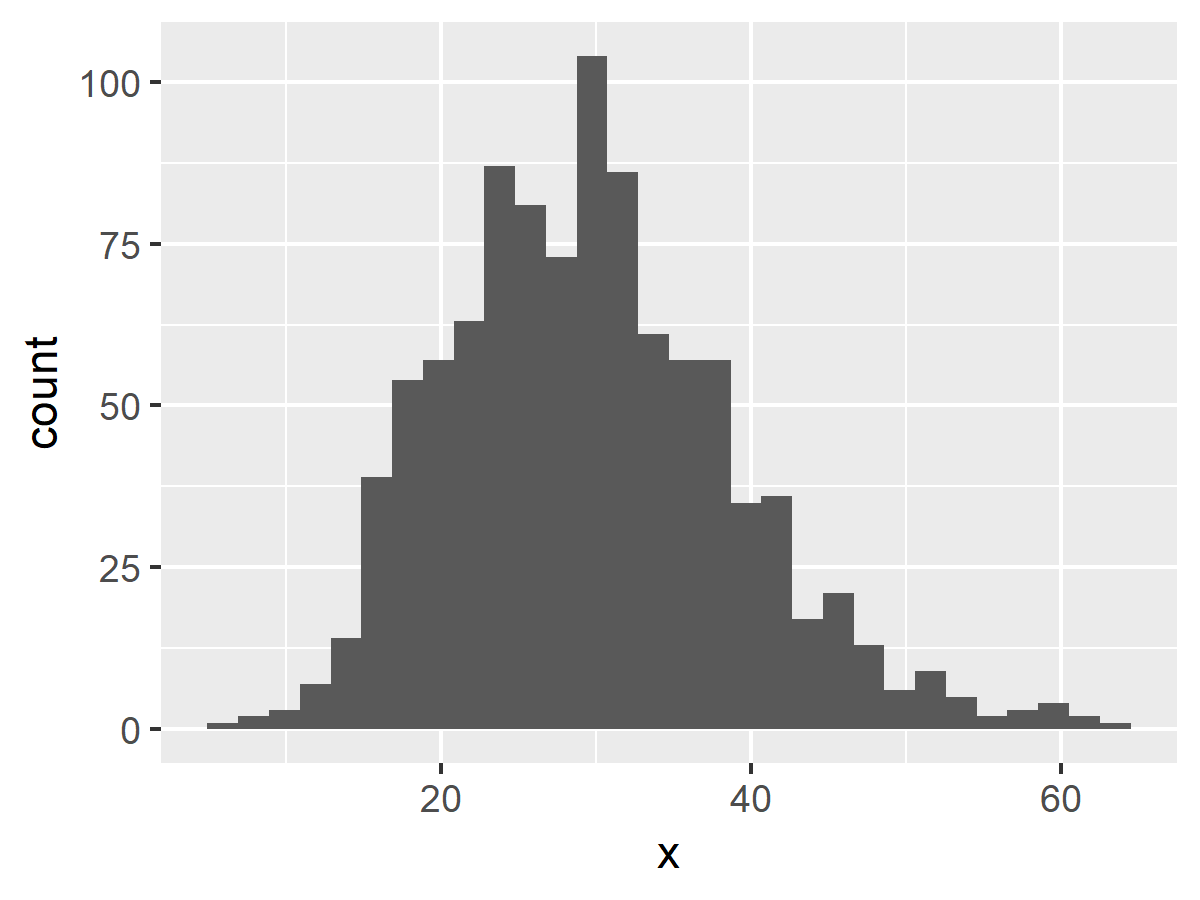
第一步的視覺化分析是最簡單的,只要將資料整理好,畫出直方圖即可:
# 載入 ggplot2 套件 library(ggplot2) # 將資料整理成 Data Frame my.df <- data.frame(x = x) # 畫出直方圖 ggplot(my.df, aes(x)) + geom_histogram()
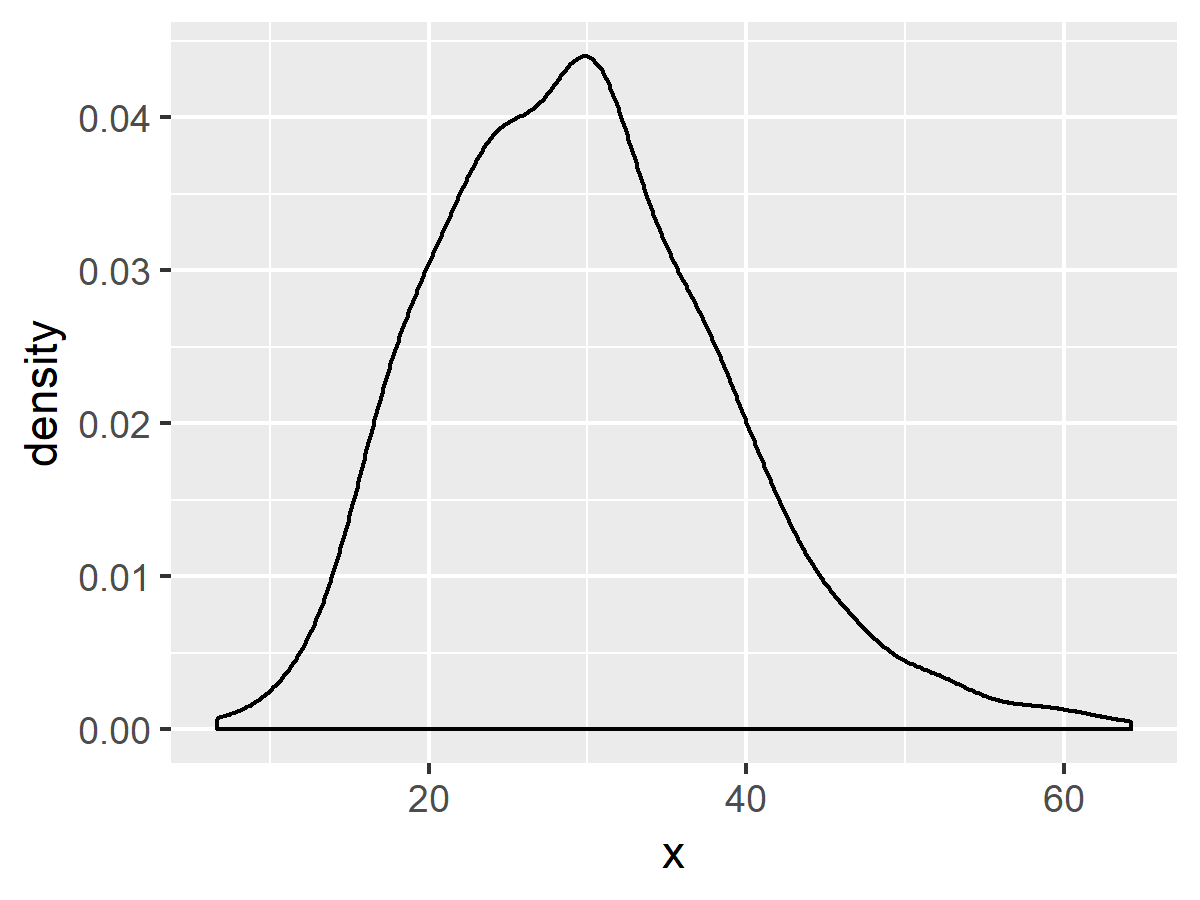
也可以畫出密度圖來觀看:
# 畫出密度圖 ggplot(my.df, aes(x)) + geom_density()
機率分佈的選擇主要是靠著自己的經驗以及對於統計分佈的基礎知識來挑選,這裡由於我們的資料是自己產生的,所以我們知道資料的分佈是來自於 Gamma,形狀參數(shape parameter)為 10,尺度參數(scale parameter)為 3。
在實務上我們會先根據畫出來的圖形猜測資料的機率分佈,以這個例子來說資料有點像是常態分佈,但是資料的分佈沒有對稱,所以我們猜它可能是 Gamma 分佈。
決定分佈之後,再估計它的各個參數值,這時候可以嘗試使用 MASS 套件的 fitdistr 函數,使用最大概似(maximum-likelihood)的方式估計各個參數:
# 載入 MASS 套件 library(MASS) # 以最大概似方法估計 Gamma 分佈的參數 fitdistr(x, dgamma, start = list(shape = 5, scale = 1))
shape scale 10.0295408 2.9545184 ( 0.4424277) ( 0.1336632)
估計出來的參數值也跟真正的值很接近。
決定好機率分布之後,接著就要進行適合度檢定,檢驗看看這個猜測的機率分佈是否合理,而適合度檢定有非常多種,在 R 中也都有對應的套件可以使用,以下是各種適合度檢定的使用方式。
卡方檢定是一個很常用的適合度檢定,不過它通常都是用於檢定離散型的分佈,若要拿來檢定連續型的資料分佈,必須先轉為離散型的分佈再進行卡方檢定:
# 將連續型的資料轉為離散型 brks <- seq(floor(min(x)), ceiling(max(x))) x.brks.counts <- table(cut(x, breaks = brks, include.lowest=FALSE, right=FALSE)) # 產生機率分佈的理論值 library('zoo') brks.cdf <- pgamma(brks, shape = 10, scale = 3) null.probs <- rollapply(brks.cdf, 2, function(x) x[2]-x[1]) # 卡方檢定 chisq.test(x.brks.counts, p = null.probs, rescale.p = TRUE, simulate.p.value = TRUE)
Chi-squared test for given probabilities with simulated p-value (based on
2000 replicates)
data: x.brks.counts
X-squared = 58.824, df = NA, p-value = 0.4428
Kolmogorov–Smirnov 檢定 是一種簡單的無母數檢定方法,它會比較實際資料與指定分佈(或參考資料)的累積分布函數(CDF),判斷兩者是否有差異。
# Kolmogorov–Smirnov 檢定 ks.test(x, "pgamma", shape = 10, scale = 3)
One-sample Kolmogorov-Smirnov test data: x D = 0.023277, p-value = 0.6507 alternative hypothesis: two-sided
Cramér-von Mises 檢定 也是一種用來檢定連續型機率分布的方法,在 R 中若要進行這種檢定,可以使用 goftest 套件。
# 載入 goftest 套件 library(goftest) # Cramer-von Mises 檢定 cvm.test(x, "pgamma", shape = 10, scale = 3)
Cramer-von Mises test of goodness-of-fit
Null hypothesis: Gamma distribution
with parameters shape = 10, scale = 3
data: x
omega2 = 0.13188, p-value = 0.4499
Anderson-Darling 檢定也是用來檢定資料是否來自於指定機率分佈的方法,在 R 中同樣可以使用 goftest 套件來處理。
# 載入 goftest 套件 library(goftest) # Anderson-Darling 檢定 ad.test(x, "pgamma", shape = 10, scale = 3)
Anderson-Darling test of goodness-of-fit
Null hypothesis: Gamma distribution
with parameters shape = 10, scale = 3
data: x
An = 0.90978, p-value = 0.4082
關於 Anderson-Darling 與 Kolmogorov–Smirnov 兩種檢定的差異,可以參考 StackExchange 的文章。
通常猜測機率分佈與檢定的過程會重複好幾次,嘗試看看不同的機率分佈所配適的結果,以下是常態分佈、t 分佈與 Gamma 分佈的比較,表中的數值是檢定的 p-value。
| 常態分佈 | t 分佈 | Gamma 分佈 | |
|---|---|---|---|
| 參數估計 | mean = 29.63 sd = 9.28 |
df = 4.66 ncp = 25.10 |
shape = 10.03 scale = 2.95 |
| 卡方檢定 | 0.001499 | 0.0004998 | 0.4518 |
| Kolmogorov–Smirnov 檢定 | 0.05591 | 5.052e-08 | 0.3787 |
| Cramér-von Mises 檢定 | 0.04791 | 6.341e-07 | 0.6286 |
| Anderson-Darling 檢定 | 0.01805 | 6e-07 | 0.7933 |
比較過各種機率分佈與檢定的結果之後,就可以比較清楚看出來哪一個機率分佈是比較適合的了。
t 分佈四種檢定結果的 p-value 都非常低,所以非常不適合,而常態分佈的檢定情況則是剛好在邊緣地帶,只有一個 Kolmogorov–Smirnov 檢定勉強通過,而 Gamma 分佈的檢定結果則是非常好,所以 Gamma 還是最適合的機率分佈。
參考資料:Ensemble Blogging
{kind=link}
{kind=link}