介紹如何在 R 中使用線性迴歸的工具,建立迴歸模型、分析與預測資料,並畫出相關的圖形。
迴歸分析(regression analysis)在統計學上是一個非常基本的數據分析方法,可以用於分析兩個或多個變數間是否相關,以及相關性的方向與強度等,在建立模型之後還可以用來預測未知的資料。
R 是一個免費且功能強大的統計分析工具,以下我們以實際的範例來示範如何使用 R 進行迴歸分析,建立迴歸模型、預測資料。
大部分的情況下我們通常都會使用 Excel 來儲存自己的數據,如果想要將 Excel 的資料讀進 R 中,最常見的方式就是先將 Excel 表格轉存為 CSV 檔案,然後在 R 中使用 read.csv 函數將資料讀進來。
這裡我們以 iris.csv 這個 CSV 檔案作為範例:
# 讀取 iris.csv my.iris.df <- read.csv("iris.csv")
read.csv 的參數就是 CSV 檔案的路徑,如果只有寫檔名的話,就會從目前的工作目錄(預設是自己的「文件」資料夾)中尋找該檔案。
如果自己的 CSV 檔案放在別的地方,也可以使用完整的絕對路徑來指定:
# 使用絕對路徑 my.iris.df <- read.csv("D:iris.csv")
由於反斜線在 R 的字串中屬於特殊的跳脫字元,所以在撰寫絕對路徑的時候,凡是要輸入反斜線的地方,都要改成兩個反斜線()。
將資料讀取進來之後,可以用 head 將資料的前幾行輸出來檢查看看:
# 查看 my.iris.df 的資料 head(my.iris.df)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
.),它不會影響到資料,只是在變數的指定時要使用新的名稱而已。將資料成功讀取進 R 中之後,接著檢查一下 my.iris.df 的內部結構:
# 查看 my.iris.df 內部結構 str(my.iris.df)
'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
在 str 的輸出中,每一行代表一個變數欄位,標示了變數名稱與類型,後面接著幾筆實際的資料,以這個例子來說,前四個變數欄位的類型是數值(num),而最後一個 Species 的類型則是類別型的因子(Factor)。
若資料型態沒有問題,再檢查所有的資料是否都完整,也就是說要看看有沒有資料含有缺失值(NA):
# 檢查是否有 NA 的資料 my.iris.df[!complete.cases(my.iris.df),]
正常來說若資料都完整的話,就會輸出空的 data frame 表格:
[1] Sepal.Length Sepal.Width Petal.Length Petal.Width Species <0 rows> (or 0-length row.names)
確認資料與類型都沒問題之後,就可以開始進行資料的分析工作了。
如果在這些檢查中,發現資料的類型不對,或是含有缺失值(NA)等問題,請參考 R 資料修正的方法來處理。
通常在開始分析資料之前,會先用 summary 看一下各個變數的基本統計量:
# 查看基本統計量 summary(my.iris.df)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50 Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50 Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
光看數字可能不是很好理解資料的分佈狀況,把資料畫出來看一下會更清楚。繪圖的方式有好多種,這裡我們示範使用 ggplot2 與 GGally 套件來畫圖的方法,首先安裝一下這兩個套件:
# 安裝 ggplot2 與 GGally 套件 install.packages(c("ggplot2", "GGally"))
載入這兩個套件:
# 載入 ggplot2 與 GGally 套件 library(ggplot2) library(GGally)
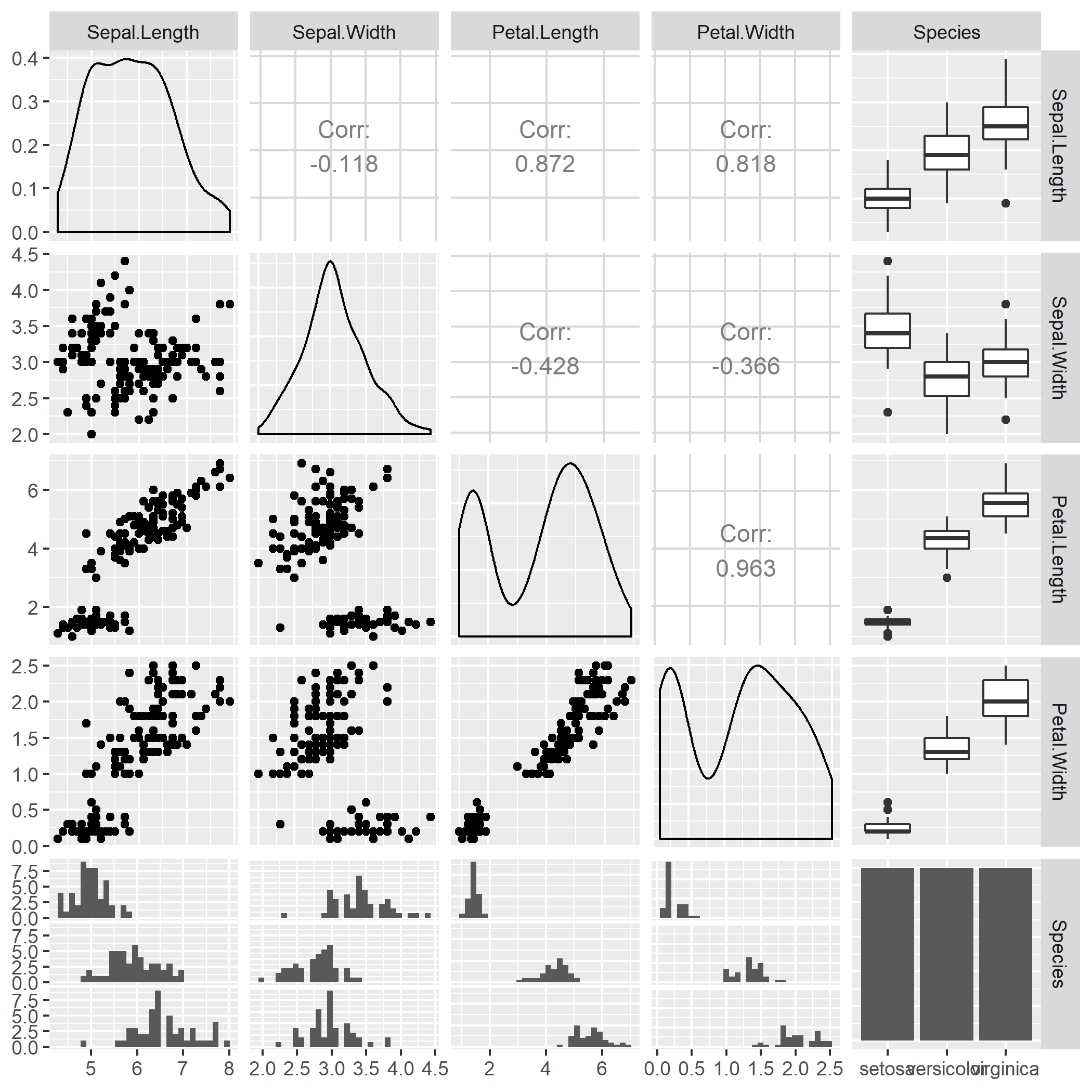
使用 ggpairs 可畫出很漂亮的資料分佈矩陣圖:
# 繪製資料分佈矩陣圖 ggpairs(my.iris.df)
如果只想畫出簡單的 XY 散佈圖,可以這樣畫:
# 畫出 XY 散佈圖 require(ggplot2) qplot(x = Petal.Length, y = Petal.Width, data = my.iris.df)
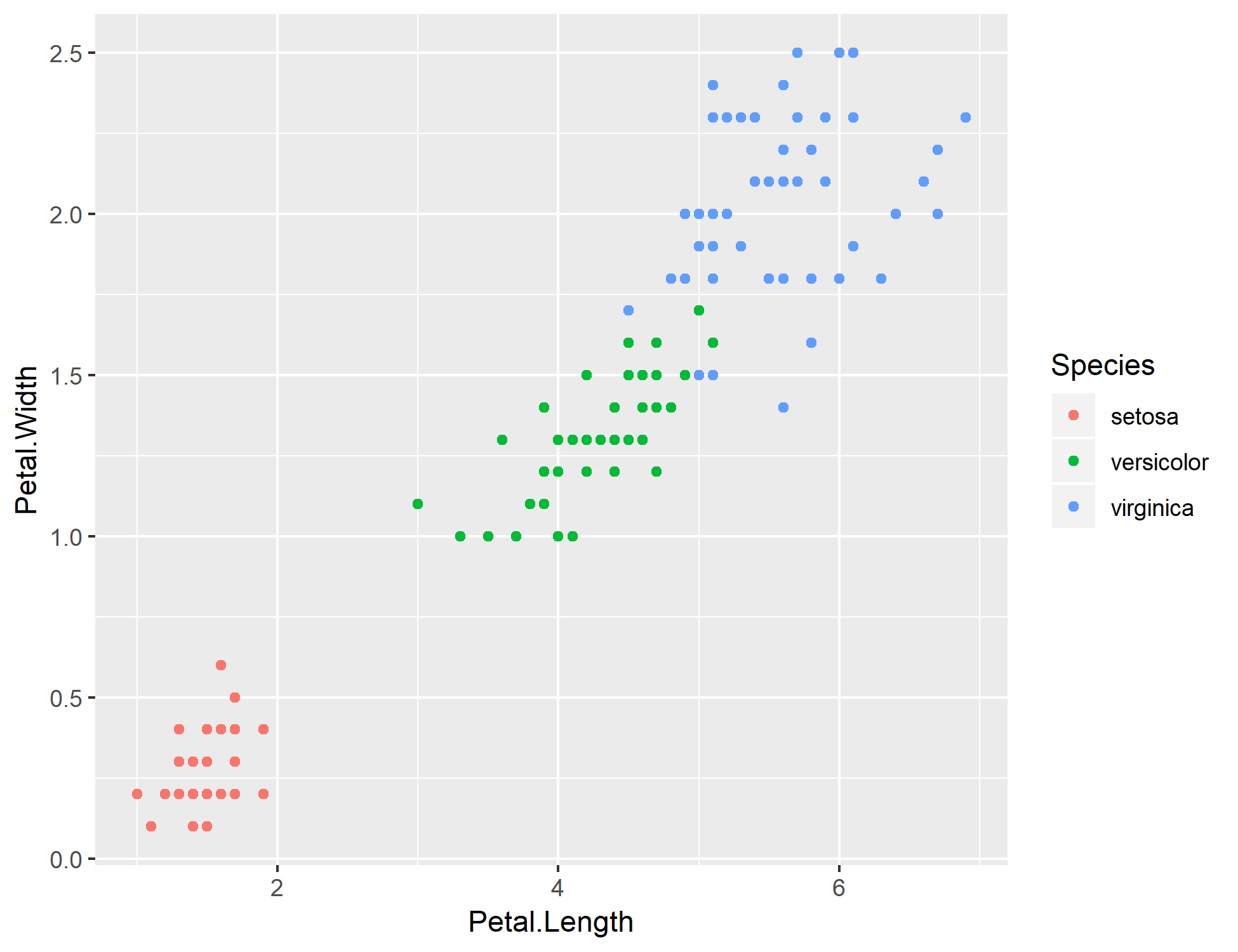
如果想要比較不同的 Species 類別的 XY 散佈圖,可以這樣畫:
# 畫出 XY 散佈圖,依據 Species 上色 require(ggplot2) qplot(x = Petal.Length, y = Petal.Width, data = my.iris.df, color = Species)
這個例子是以 Petal.Length 與 Petal.Width 當作 X 與 Y 的座標,若要使用別的變數欄位,就直接把變數名稱替換掉即可。
建立迴歸模型可以使用 lm 這個函數(lm 代表 linear models),假設我們想要拿 Sepal.Length 作為反應變數(也就是 Y),而 Sepal.Width、Petal.Length 與 Petal.Width 作為解釋變數(也就是 X),則可以執行:
# 建立迴歸模型 iris.lm <- lm(Sepal.Length ~ Sepal.Width + Petal.Length + Petal.Width, data = my.iris.df)
其中第一個參數放的就是所謂的公式(formula),它用來表示迴歸模型的一種表示法,中間的 ~ 相當於迴歸公式的等號,左邊的 Sepal.Length 就是 Y,而右邊放的三個變數則是 X。第二個參數 data 則是用來指定資料來源的 data frame。
建立好迴歸模型之後,可以使用 summary 查看模型配適的結果:
# 查看模型配適結果 summary(iris.lm)
Call:
lm(formula = Sepal.Length ~ Sepal.Width + Petal.Length + Petal.Width,
data = my.iris.df)
Residuals:
Min 1Q Median 3Q Max
-0.82816 -0.21989 0.01875 0.19709 0.84570
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.85600 0.25078 7.401 9.85e-12 ***
Sepal.Width 0.65084 0.06665 9.765 < 2e-16 ***
Petal.Length 0.70913 0.05672 12.502 < 2e-16 ***
Petal.Width -0.55648 0.12755 -4.363 2.41e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3145 on 146 degrees of freedom
Multiple R-squared: 0.8586, Adjusted R-squared: 0.8557
F-statistic: 295.5 on 3 and 146 DF, p-value: < 2.2e-16
從這份輸出的結果中,我們可以看出各個解釋變數的係數,若將整個模型寫出來就會像這樣:
Sepal.Length = 0.65084 * Sepal.Width
+ 0.70913 * Petal.Length
- 0.55648 * Petal.Width
+ 1.856
報表中的 Pr(>|t|) 就是統計上的 p-value,以這裡的值來說,每一個係數都非常顯著。
R-squared 的值為 0.8586,Adjusted R-squared 的值為 0.8557,表示模型的配適情況不錯。
在配適完迴歸模型之後,接著要進行模型診斷,通常會先畫出幾張常用來診斷模型的圖,這裡我們用 ggfortify 這個套件來畫圖,它畫出來的圖會比較漂亮。
# 安裝並載入 ggfortify 套件 install.packages("ggfortify") library(ggfortify)
接著畫出模型診斷用的圖:
# 畫出模型診斷用的圖 autoplot(iris.lm)
以這幾張圖來說都算滿標準的,沒有特殊的趨勢或是奇怪的地方,看起來都正常。
在理論上迴歸模型配適完成後,其殘差值(residual)必須符合常態性(normality)、獨立性(independence)以及變異數同質性(homogeneity of variance)三種假設,所以接下來要用三種檢定檢查這三個條件是否符合。
shapiro.test 函數可以用來檢定殘差值是否符合常態分佈:
# 常態性檢定 shapiro.test(iris.lm$residual)
Shapiro-Wilk normality test data: iris.lm$residual W = 0.99559, p-value = 0.9349
常態性檢定的 p-value 非常高,所以不拒絕虛無假設,也就是說殘差值的常態分配假設是合理的。
獨立性檢定要使用到 car 這個套件,使用前要先安裝它:
# 安裝 car 套件 install.packages("car")
呼叫 durbinWatsonTest 函數進行獨立性檢定:
# 殘差獨立性檢定 require(car) durbinWatsonTest(iris.lm)
lag Autocorrelation D-W Statistic p-value 1 -0.03992126 2.060382 0.822 Alternative hypothesis: rho != 0
殘差獨立性檢定的 p-value 也非常高,所以也不拒絕虛無假設,亦即殘差值的獨立性假設是合理的。
殘差的變異數同質性檢定可以使用 car 套件所提供的 函數:
# 殘差變異數同質性檢定 require(car) ncvTest(iris.lm)
Non-constant Variance Score Test Variance formula: ~ fitted.values Chisquare = 4.448612 Df = 1 p = 0.03492962
殘差變異數同質性檢定的 p-value 稍微偏小,以一般 95% 的信賴水準來說,是拒絕虛無假設的,也就是說殘差的變異數沒有符合同質性的假設,但是因為這個 p-value 並沒有非常小,所以證據並不是非常明確。
在迴歸模型建立好之後,就可以利用這個模型來預測新的資料,假設我們收到一些新的觀測值(解釋變數 X):
# 新觀測值 new.iris <- data.frame(Sepal.Width=3.1, Petal.Length=1.6, Petal.Width=0.3) new.iris
Sepal.Width Petal.Length Petal.Width 1 3.1 1.6 0.3
若要使用迴歸模型預測新的反應變數,可以使用 predict 函數:
# 預測資料 predict(iris.lm, new.iris)
1 4.841259
預測出來的 Sepal.Length 值就是 4.841259。
參考資料:RPubs
{kind=link}
{kind=link}
{kind=link}
{kind=link}