以範例說明在 R 中如何使用資料的 QQ 圖形與常態性檢定,判斷資料是否來自於常態分佈。
這裡我們產生一組常態分佈的資料 x,以及一組不是常態分佈的資料 y:
# 設定亂數種子 set.seed(3) # 常態分佈 x = rnorm(100, 8, 2) # 不是常態分佈 y = rweibull(100, 2, 6)
使用直方圖看一下產生的資料狀況:
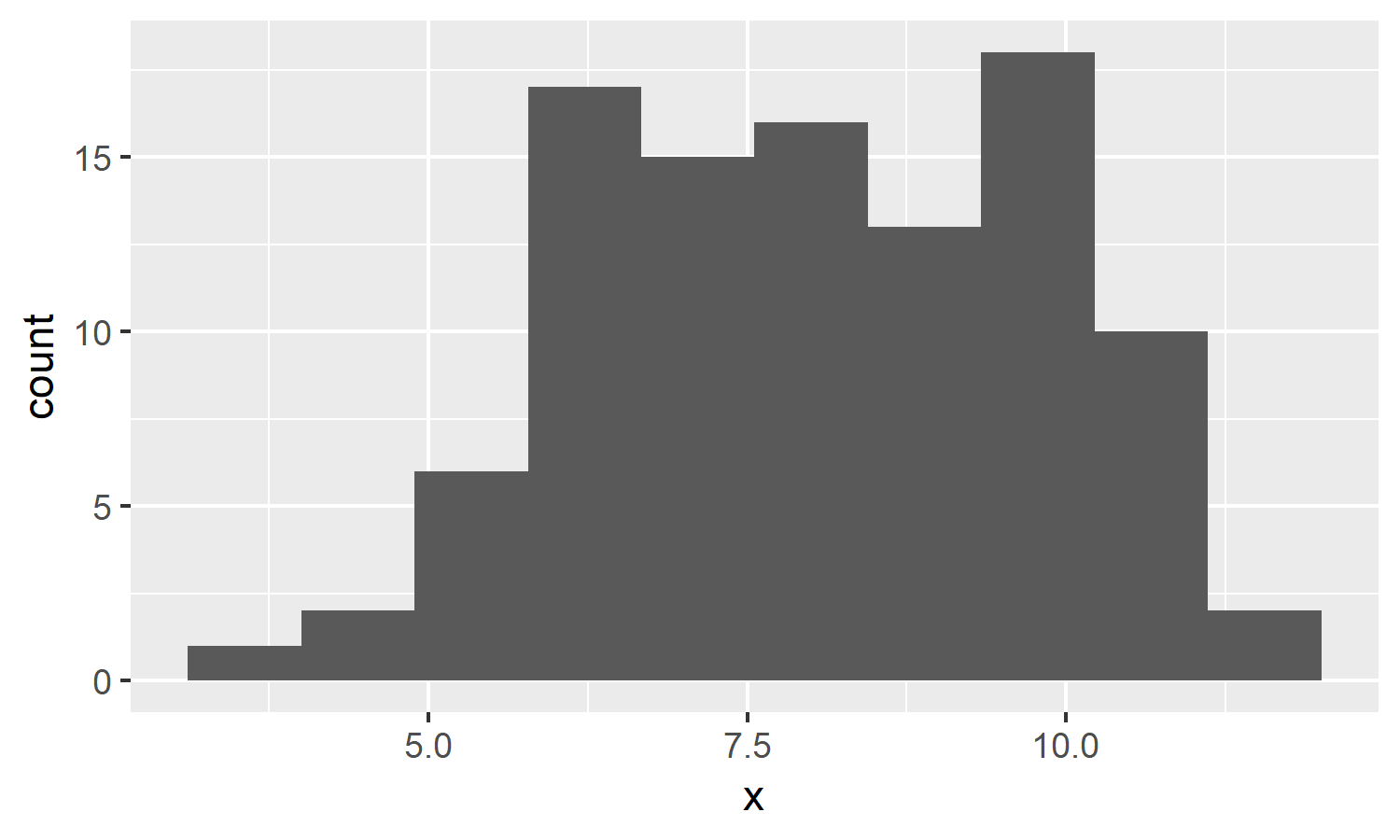
# 載入 ggplot2 套件 library(ggplot2) # 畫出 x 的直方圖 ggplot(data.frame(x=x), aes(x)) + geom_histogram()
x 的直方圖
從 x 的直方圖看起來,它雖然是從常態分佈產生的,但是可能運氣不好,剛好資料的分佈不是很漂亮。
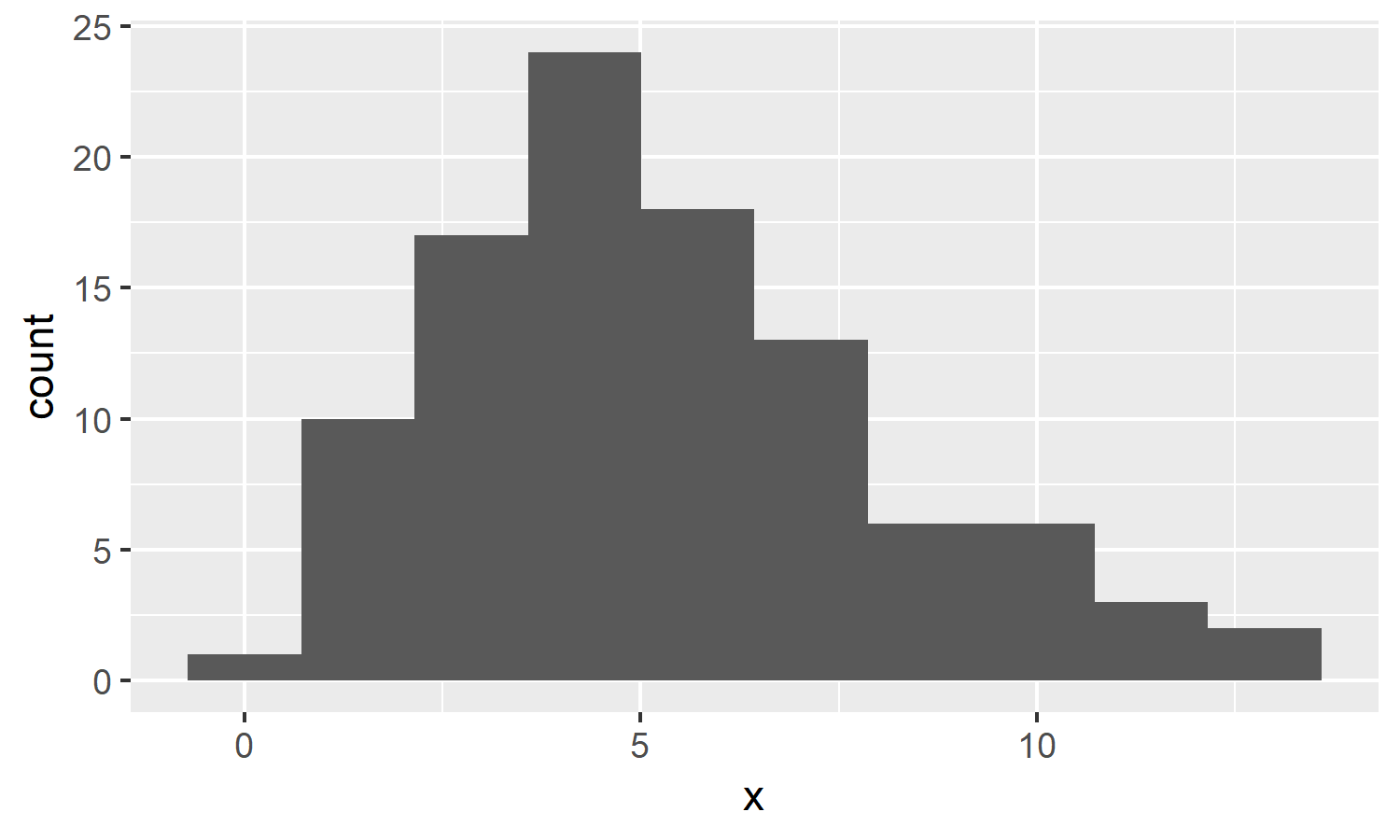
# 畫出 y 的直方圖 ggplot(data.frame(x=y), aes(x)) + geom_histogram()
接下來我們就要開始用各種方式來檢查 x 與 y 是否來自於常態分佈。
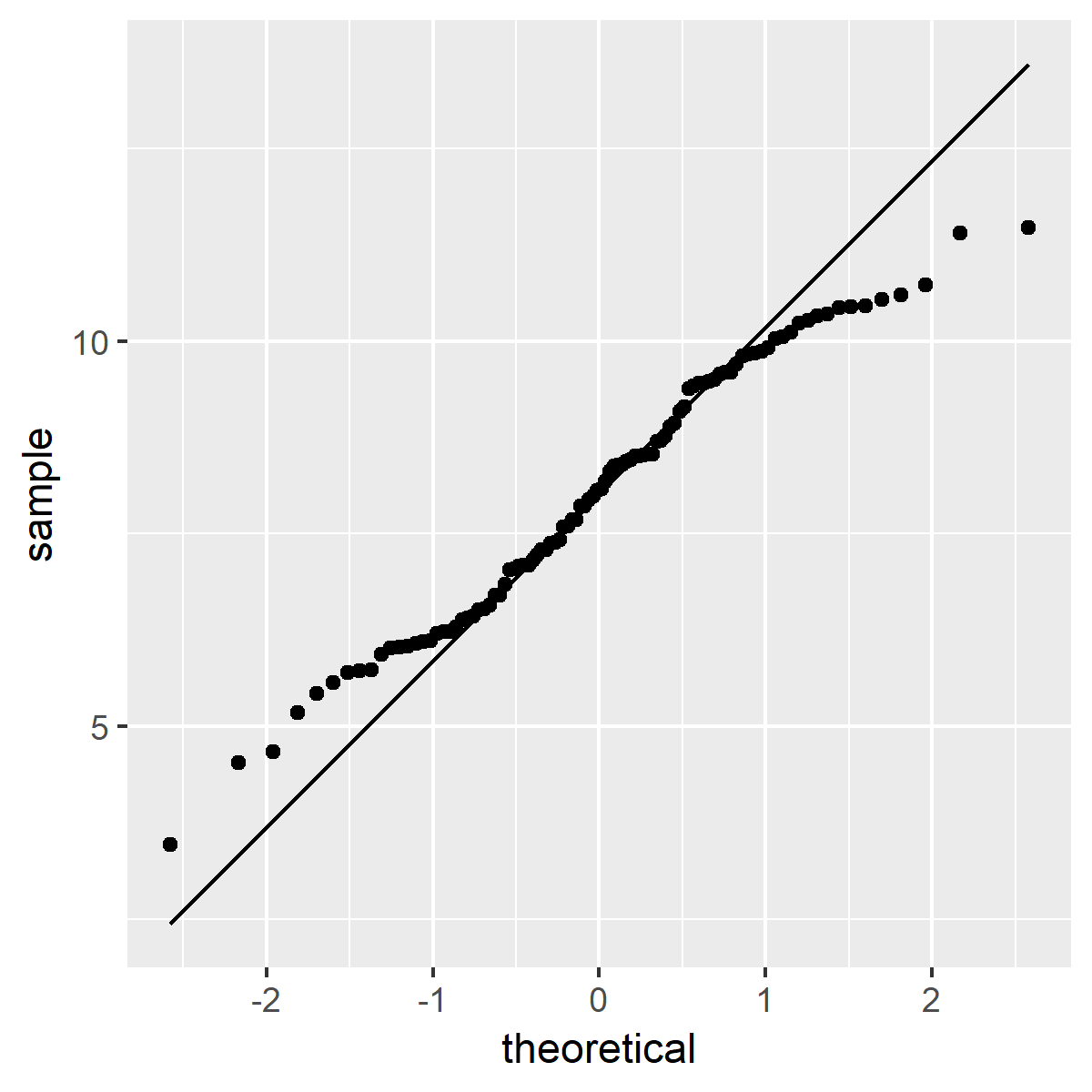
通常在一開始拿到資料的時候,都會畫一下 QQ 圖(quantile-quantile plot),這種圖形可用來比較資料與常態分佈之間的差異,圖中那一條直線是理論值,如果是完美的常態分佈,所有的點就都會落在直線上。
# 畫出 x 的 QQ 圖 ggplot(data.frame(x=x), aes(sample=x)) + stat_qq() + stat_qq_line()
x 的 QQ 圖
從 QQ 圖看起來,x 的分佈不是非常接近常態分佈(雖然它實際上是)。
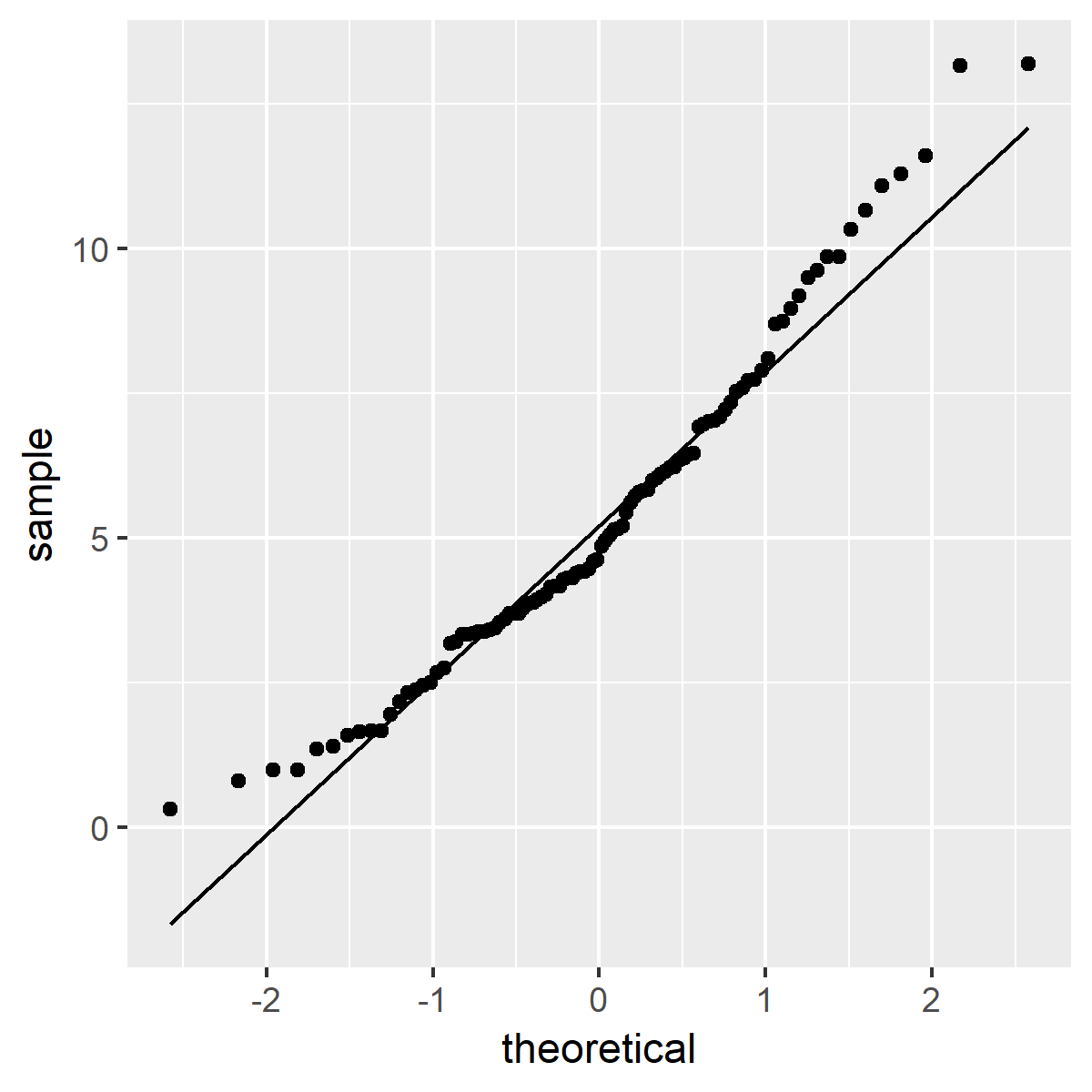
#畫出 y 的 QQ 圖 ggplot(data.frame(x=y), aes(sample=x)) + stat_qq() + stat_qq_line()
y 的 QQ 圖
y 的 QQ 圖看起來跟 x 的 QQ 圖似乎差不多。
在 R 中若要進行常態性檢定,最常用的方式就是 Shapiro-Wilk 檢定,它是 R 內建的統計檢定,不需要安裝套件即可使用:
# Shapiro-Wilk 常態性檢定 shapiro.test(x)
Shapiro-Wilk normality test data: x W = 0.97928, p-value = 0.1167
x 經過檢定後,p-value 為 0.1167,不拒絕虛無假設(也就是符合常態分佈)。
# Shapiro-Wilk 常態性檢定 shapiro.test(y)
Shapiro-Wilk normality test data: y W = 0.96226, p-value = 0.005847
而在 y 的檢定結果中,p-value 非常小,所以拒絕虛無假設,表示 y 不符合常態分佈。
nortest 套件除了 Shapiro-Wilk 檢定之外,如果想嘗試其他的統計檢定方法的話,可以安裝 nortest 套件,這個套件中提供了好幾種專門用於常態性檢定的方法。
# 安裝 nortest 套件 install.packages("nortest") # 載入 nortest 套件 library(nortest)
安裝並載入 nortest 套件之後,就可以使用各種的檢定函數,以下是這些檢定函數的用法。
Anderson-Darling 常態性檢定可以使用 ad.test 函數:
# Anderson-Darling 檢定 ad.test(x)
Anderson-Darling normality test data: x A = 0.70069, p-value = 0.06534
# Anderson-Darling 檢定 ad.test(y)
Anderson-Darling normality test data: y A = 1.0642, p-value = 0.008167
Cramer-von Mises 常態性檢定可以使用 cvm.test 函數:
# Cramer-von Mises 檢定 cvm.test(x)
Cramer-von Mises normality test data: x W = 0.10654, p-value = 0.08997
# Cramer-von Mises 檢定 cvm.test(y)
Cramer-von Mises normality test data: y W = 0.17758, p-value = 0.01014
Lilliefors 常態性檢定可以使用 lillie.test 函數:
# Lilliefors 檢定 lillie.test(x)
Lilliefors (Kolmogorov-Smirnov) normality test data: x D = 0.085681, p-value = 0.06743
# Lilliefors 檢定 lillie.test(y)
Lilliefors (Kolmogorov-Smirnov) normality test data: y D = 0.10268, p-value = 0.01124
Pearson Chi-Squared 常態性檢定可以使用 pearson.test 函數:
# Pearson Chi-Squared 檢定 pearson.test(x)
Pearson chi-square normality test data: x P = 18.04, p-value = 0.05429
# Pearson Chi-Squared 檢定 pearson.test(y)
Pearson chi-square normality test data: y P = 20.64, p-value = 0.02375
Shapiro-Francia 常態性檢定可以使用 sf.test 函數:
# Shapiro-Francia 檢定 sf.test(x)
Shapiro-Francia normality test data: x W = 0.98175, p-value = 0.1579
# Shapiro-Francia 檢定 sf.test(y)
Shapiro-Francia normality test data: y W = 0.96481, p-value = 0.01071
x 經過各種常態性的檢定之後,雖然都不拒絕虛無假設,但是得到的 p-value 都在 0.05 附近,所以只能勉強算是常態分佈。
而 y 的檢定結果都是拒絕虛無假設,大部分的 p-value 也不會太大,所以比較可以確定它不是常態分佈。
參考資料:RPubs、datascience+
{kind=link}
{kind=link}
{kind=link}
{kind=link}