介紹如何使用 R 的 pheatmap 套件畫出精緻的熱圖(heatmap)。
pheatmap 套件R 的 CRAN 官方套件庫就有收錄 pheatmap 套件,所以可以直接使用 install.packages 安裝:
# 安裝 pheatmap 套件 install.packages("pheatmap")
若在自動化的指令稿中,可以這樣寫:
# 自動安裝與載入 pheatmap 套件 if(!require(pheatmap)){ install.packages("pheatmap") library(pheatmap) }
pheatmap 在繪製熱圖的時候,主要的資料是以數值矩陣的格式傳入,以下我們先產生一個測試用的矩陣資料:
# 建立測試用矩陣資料 set.seed(1) mat <- matrix(rnorm(200), 20, 10) mat[1:10, seq(1, 10, 2)] <- mat[1:10, seq(1, 10, 2)] + 3 mat[11:20, seq(2, 10, 2)] <- mat[11:20, seq(2, 10, 2)] + 2 mat[15:20, seq(2, 10, 2)] <- mat[15:20, seq(2, 10, 2)] + 4
pheatmap 在繪製熱圖的時候,會使用到矩陣的行與列名稱作為資料對應的依據以及文字標示,所以建議將行與列的名稱也都設定好:
# 設定矩陣的行與列名稱 colnames(mat) <- paste("Test", 1:10, sep = "") rownames(mat) <- paste("Gene", 1:20, sep = "")
查看產生的矩陣資料:
# 查看矩陣 head(mat)
Test1 Test2 Test3 Test4 Test5 Test6 Test7
Gene1 2.373546 0.91897737 2.835476 2.40161776 2.431331 -0.62036668 2.494043
Gene2 3.183643 0.78213630 2.746638 -0.03924000 2.864821 0.04211587 4.343039
Gene3 2.164371 0.07456498 3.696963 0.68973936 4.178087 -0.91092165 2.785421
Gene4 4.595281 -1.98935170 3.556663 0.02800216 1.476433 0.15802877 2.820443
Gene5 3.329508 0.61982575 2.311244 -0.74327321 3.593946 -0.65458464 2.899809
Gene6 2.179532 -0.05612874 2.292505 0.18879230 3.332950 1.76728727 3.712666
Test8 Test9 Test10
Gene1 -1.9143594 3.425100 -1.2313234
Gene2 1.1765833 2.761353 0.9838956
Gene3 -1.6649724 4.058483 0.2199248
Gene4 -0.4635304 3.886423 -1.4672500
Gene5 -1.1159201 2.380757 0.5210227
Gene6 -0.7508190 5.206102 -0.1587546
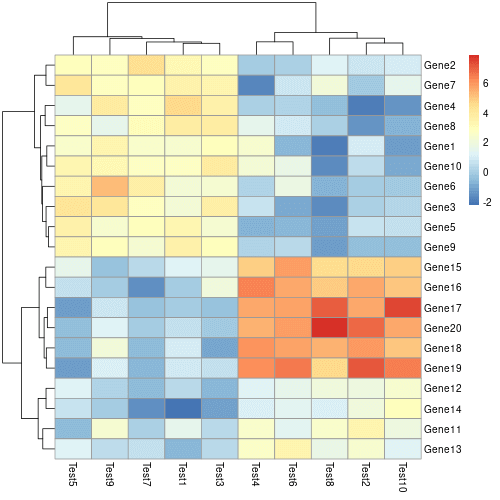
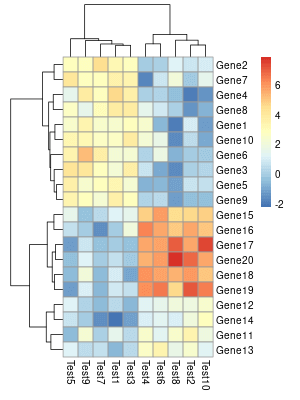
建立好矩陣資料之後,就可以直接呼叫 pheatmap 繪製基本的熱圖:
# 基本熱圖 pheatmap(mat)
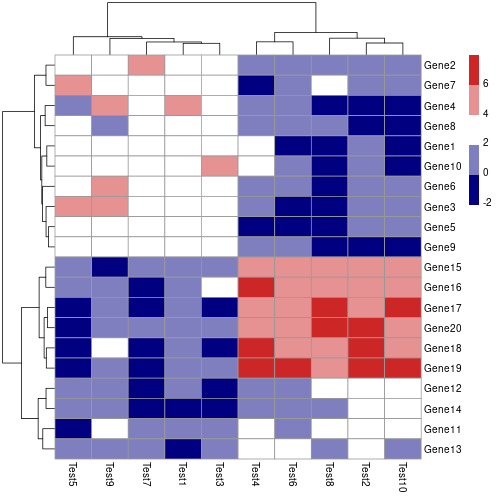
若要改變熱圖的顏色,可以使用 color 參數自訂色盤:
# 自訂顏色 pheatmap(mat, color = colorRampPalette(c("navy", "white", "firebrick3"))(5))
在圖形的左側有一個色盤對應表,如果不想顯示它,可以將 legend 設為 FALSE。
# 不顯示色盤對應表 pheatmap(mat, legend = FALSE)
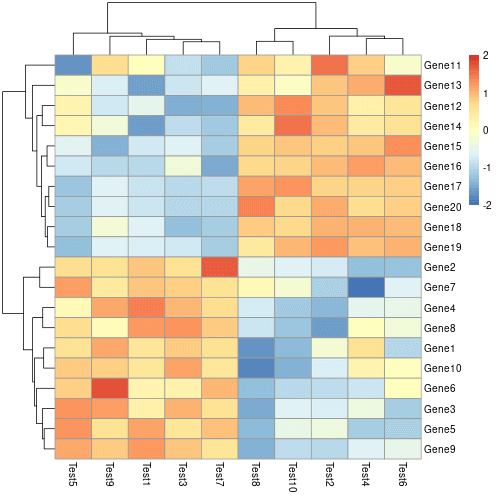
如果需要在繪製熱圖時,先將數值進行標準化(平均值調整為 0,標準差調整為 1),可以加上 scale 參數,並指定要依照行(column)或列(row)進行標準化:
# 以列(row)的方向進行數值的標準化 pheatmap(mat, scale = "row")
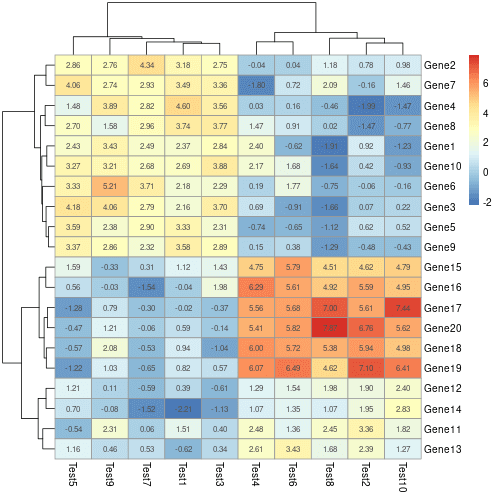
若要將實際的數值直接標示在熱圖之中,可以加上 display_numbers 參數:
# 標示數值 pheatmap(mat, display_numbers = TRUE)
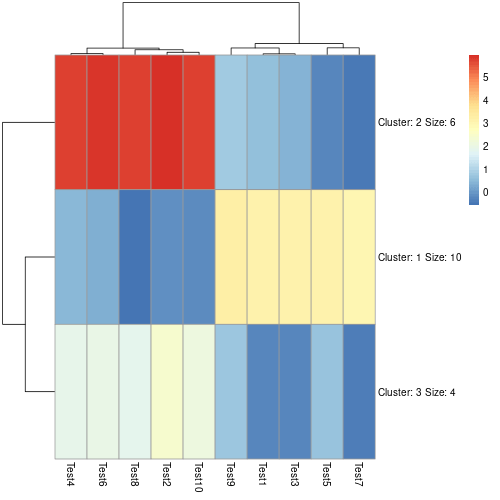
若要自動將矩陣的列先以 K-means 分群好再畫熱圖,可以加上 kmeans_k 參數指定分群數:
# 使用 K-means 將矩陣的列做分群 pheatmap(mat, kmeans_k = 3)
pheatmap 預設會使用歐式距離(Euclidean distance)作為分群的基準,亦可改用皮爾遜積矩相關係數(Pearson correlation),這部份可以透過 clustering_distance_rows 與 clustering_distance_cols 來調整:
# 以相關係數分群 pheatmap(mat, clustering_distance_rows = "correlation")
如果不想進行分群,可以直接透過 cluster_rows 與 cluster_cols 將分群功能關閉:
# 不進行列方向的分群 pheatmap(mat, cluster_row = FALSE)
另外亦可自己定義距離矩陣進行分群:
# 自訂距離矩陣,進行分群 drows = dist(mat, method = "minkowski") dcols = dist(t(mat), method = "minkowski") pheatmap(mat, clustering_distance_rows = drows, clustering_distance_cols = dcols)
如果要固定熱圖中格子的大小,可以使用 cellwidth 與 cellheight 來設定格子的寬度與高度:
# 固定格子的大小 pheatmap(mat, cellwidth = 15, cellheight = 15)
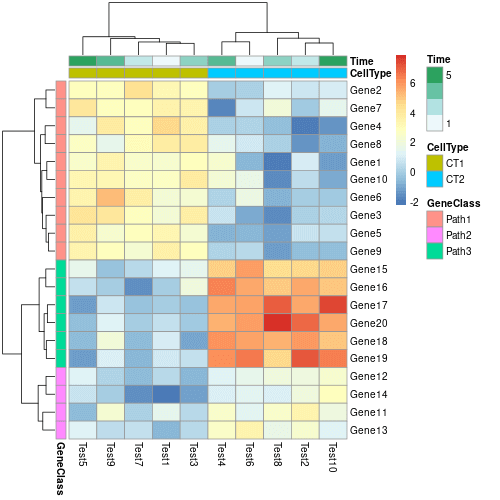
我們也可以在熱圖的周圍加上一些標注資訊,顯示資料的其他各種屬性。標注可以加在矩陣的行或列上,這裡我們先產生行與列的標注資料。
# 產生行的標注資訊 annotation_col = data.frame( CellType = factor(rep(c("CT1", "CT2"), 5)), Time = 1:5) rownames(annotation_col) = paste("Test", 1:10, sep = "") # 產生列的標注資訊 annotation_row = data.frame( GeneClass = factor(rep(c("Path1", "Path2", "Path3"), c(10, 4, 6)))) rownames(annotation_row) = paste("Gene", 1:20, sep = "")
在建立標注資料時,要注意 rownames 的設定要跟之前矩陣的 rownames 與 colnames 設定吻合。
有了標注資料,就可以透過 annotation_col 與 annotation_row 在熱圖中加入標注資訊:
# 加上行與列的標注資訊 pheatmap(mat, annotation_col = annotation_col, annotation_row = annotation_row)
如果要關閉右側的標注資訊的對照表,可將 annotation_legend 設定為 FALSE:
# 關閉標注資訊的對照表 pheatmap(mat, annotation_col = annotation_col, annotation_legend = FALSE)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}