使用 R 讀取 CSV、JSON、XML 這些常見的檔案格式,檢查並修正各類型的錯誤資料。
使用 R 進行各種資料的分析之前,一定要先把資料讀進 R 中,以下我們將介紹各種常見檔案格式的讀取方式,以及實務上常用的資料修正方法。
CSV 檔案是一種以逗點分隔各欄位的檔案格式,大部分的資料分析軟體都支援這樣的格式(Excel 亦可匯出為 CSV 檔),而 R 本身也內建了讀寫 CSV 檔案的函數。
如果要讀取 CSV 檔案,可以使用內建的 read.csv 函數,例如若要讀取 iris.csv 這個檔案,則可執行:
# 讀取 iris.csv my.df <- read.csv("iris.csv")
讀進來之後,先用 head 查看一下前幾筆資料:
# 查看前幾筆資料 head(my.df)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
再用 str 檢查一下資料的型態:
# 檢查資料型態 str(my.df)
'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
順便看一下基本的統計量:
# 基本統計量 summary(my.df)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50 Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50 Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
若確認資料沒問題的話,這樣就完成 CSV 資料的讀取動作了。
若想要在 R 中讀取 JSON 格式的資料,必須依靠 JSON 相關的套件,而這類的套件有很多種,這裡我們介紹使用 jsonlite 套件來讀取 JSON 檔案的方法。
使用前要先安裝 jsonlite 套件:
# 安裝 jsonlite 套件 install.packages("jsonlite")
接著載入此套件:
# 載入 jsonlite 套件 library(jsonlite)
若要讀取普通的 JSON 檔案,可以使用 fromJSON 函數:
# 讀取 JSON 檔案 my.data <- fromJSON("my_data.json")
fromJSON 也可以接受 JSON 檔案的網址,直接從網路上下載資料,以下是下載即時紫外線監測資料的範例:
# 紫外線即時監測 JSON 資料網址 url <- "http://opendata.epa.gov.tw/ws/Data/UV/?format=json" # 使用 jsonlite 下載 JSON 資料 my.data <- fromJSON(url) # 查看資料 head(my.data)
County PublishAgency PublishTime SiteName UVI WGS84Lat WGS84Lon 1 花蓮縣 中央氣象局 2018-08-19 07:00 花蓮 0.28 23,58,30 121,36,48 2 連江縣 中央氣象局 2018-08-19 07:00 馬祖 0.22 26,10,09 119,55,24 3 高雄市 中央氣象局 2018-08-19 07:00 高雄 0.17 22,33,58 120,18,57 4 南投縣 中央氣象局 2018-08-19 07:00 玉山 0.43 23,29,15 120,57,34 5 臺南市 中央氣象局 2018-08-19 07:00 臺南 0.21 22,59,36 120,12,17 6 新竹縣 中央氣象局 2018-08-19 07:00 新竹 0.30 24,49,40 121,00,51
關於 jsonlite 套件的詳細使用教學,請參考 G. T. Wang 的教學文章。
若要讀取 XML 檔案,也是有非常多的套件可用,這裡我們選用 XML 這個套件:
# 安裝 XML 套件 install.packages("XML") # 載入 XML 套件 library(XML)
XML 檔案可用 xmlParse 函數來讀取,它可以接受普通的檔案路徑以及 URL 網址,以下示範從網路上下載 XML 檔案並讀取成 data frame 的方法:
# XML 檔案網址 url <- "http://opendata2.epa.gov.tw/AQX.xml" # 下載並解析 XML 檔案 xml.doc <- xmlParse(url) # 取出 XML 的根節點 xml.top <- xmlRoot(xml.doc) # 將 XML 文件轉為 Data Frame xml.df <- xmlToDataFrame(xml.top) # 查看資料 head(xml.df)
CO County FPMI MajorPollutant NO NO2 NOx O3 PM10 PM2.5 PSI PublishTime SiteName SO2 Status WindDirec WindSpeed 1 0.32 基隆市 2 1.26 15 16.12 12 25 16 29 2017-08-02 01:00 基隆 3.3 良好 240 1.9 2 0.43 新北市 2 3.99 18 22.23 10 36 19 35 2017-08-02 01:00 汐止 4 良好 243 1 3 0.14 新北市 2 1.27 4.1 5.35 16 33 14 35 2017-08-02 01:00 萬里 2.2 良好 206 2.6 4 0.24 新北市 2 1.65 7.6 9.28 14 40 14 38 2017-08-02 01:00 新店 1 良好 48 0.8 5 0.32 新北市 2 1.47 13 14.33 14 42 20 43 2017-08-02 01:00 土城 4.1 良好 273 1.5 6 0.47 新北市 2 2.68 20 23.08 6.8 52 20 45 2017-08-02 01:00 板橋 3.1 良好 215 1.6
關於 XML 套件的詳細使用教學,請參考 G. T. Wang 的教學文章。
將資料讀取進 R 之後,一定要檢查資料的內容、變數的型態是否正確,如果發現有問題的話,就要進行修正的動作,最常見的問題就是「連續型」與「類別型」資料的誤判(也就是把數值的資料視為類別,或是反過來把類別的資料視為數值),以及資料的缺失值處理問題。
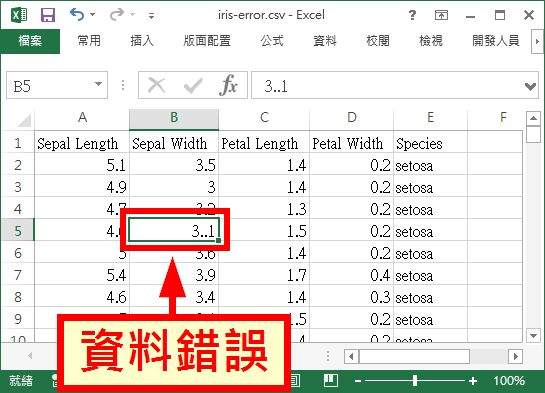
假設我們的數值資料中,含有一些錯誤的資料,例如不小心在打字的時候,多打了一個小數點等等。
而當 R 在遇到這樣的資料時,它還是可以正常讀取,並不會產生錯誤:
# 讀取 iris-error.csv error.df <- read.csv("iris-error.csv")
只不過當我們檢查資料型態的時候,那些含有錯誤資料的數值欄位就會有問題:
# 檢查資料型態 str(error.df)
'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : Factor w/ 24 levels "2","2.2","2.3",..: 16 10 13 11 17 20 15 15 9 12 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
Sepal.Width 正常來說應該是屬於數值型態(num)的欄位,但是因為一筆錯誤的資料,造成 R 將這一欄誤判為類別型的因子(Factor)。
這樣的誤判結果會直接造成後續在分析資料上的問題,例如在畫直方圖的時候,就會出現錯誤:
# 繪製直方圖 hist(error.df$Sepal.Width)
Error in hist.default(error.df$Sepal.Width) : 'x' must be numeric
解決的方式就是要把 Sepal.Width 修正回數值型的變數:
# 修正資料 corrected.df <- error.df corrected.df$Sepal.Width <- as.numeric(as.character(error.df$Sepal.Width))
資料經過修正之後,Sepal.Width 就會恢復成正常的數值型資料,而那一筆錯誤的資料就會轉為 NA。
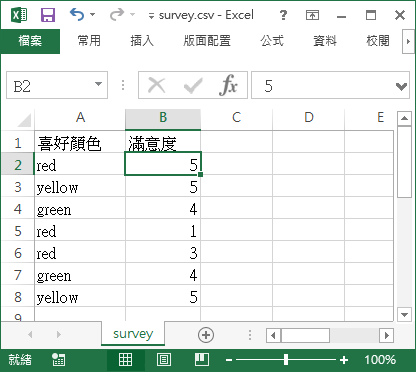
假設我們有一些類別型的資料如下,其中有顏色與滿意度的欄位。
當 R 遇到這樣的資料時,由於顏色是直接以名稱表示,所以讀進來之後會轉為正確的因子變數,但是滿意度的欄位是用數字表示,所以 R 會把它當作是數值:
# 讀取 survey.csv survey.df <- read.csv("survey.csv") # 檢查資料型態 str(survey.df)
'data.frame': 7 obs. of 2 variables: $ 喜好顏色: Factor w/ 3 levels "green","red",..: 2 3 1 2 2 1 3 $ 滿意度 : int 5 5 4 1 3 4 5
這樣計算機本統計量時,將滿意度當成數值計算,就會有些問題:
# 基本統計量 summary(survey.df)
喜好顏色 滿意度
green :2 Min. :1.000
red :3 1st Qu.:3.500
yellow:2 Median :4.000
Mean :3.857
3rd Qu.:5.000
Max. :5.000
修正的方式很簡單,只要使用 factor 將其轉為因子即可:
# 修正資料 corrected.df <- survey.df corrected.df$滿意度 <- factor(corrected.df$滿意度)
這樣在計算基本的統計量時,就會以比較有意義的方式呈現:
# 基本統計量 summary(corrected.df)
喜好顏色 滿意度
green :2 1:1
red :3 3:1
yellow:2 4:2
5:3
NA)的處理若原始資料因為某些因素,造成部分資料遺失、損毀等等狀況,就會以 NA 來表示,通常遇到這樣的資料在讀進 R 之後,也要稍微處理一下。
假設我們有一份含有 NA 的 data frame:
# 含有 NA 的 Data Frame has.na.df <- data.frame( x = c(1,NA,3,NA,5), y = 5:1 )
遇到 NA 的時候,我們可以先看一下那些含有 NA 的資料:
# 查看含有 NA 的資料 has.na.df[!complete.cases(has.na.df),]
x y 2 NA 4 4 NA 2
最常見的處理方式就是把含有 NA 的那些資料忽略掉,不要用它,na.omit 函數會將所有含有 NA 的資料刪除,只留下完整的資料:
# 忽略含有 NA 的資料 omit.na.df <- na.omit(has.na.df) omit.na.df
x y 1 1 5 3 3 3 5 5 1
{kind=link}
{kind=link}